LLM-as-a-Judge giải thích: pattern đánh giá AI Agent bằng chính LLM với rubric correctness, relevance và helpfulness
Người học hiểu được pattern LLM-as-a-Judge: cách dùng một LLM mạnh để chấm điểm output của AI Agent theo rubric (correctness, relevance, helpfulness),
Bạn build xong một AI Agent, chạy 200 query test, giờ chấm điểm thế nào? Thuê human review thì đắt và chậm, dùng BLEU/ROUGE thì miss nuance. LLM-as-a-Judge là pattern dùng một LLM mạnh chấm output của agent theo rubric rõ ràng. Bài này mình mổ xẻ cách thiết kế rubric 3 chiều (correctness, relevance, helpfulness), code judge bằng Claude trong 40 dòng TypeScript, so sánh pairwise vs single-score, và 4 bias kinh điển cần mitigate trước khi đưa lên production.
LLM-as-a-Judge là gì và vì sao dev cần biết
LLM-as-a-Judge (hay Judge LLM) là một phương pháp đánh giá output của các mô hình ngôn ngữ lớn (LLM) khác bằng cách sử dụng một LLM mạnh hơn. Thay vì dựa vào con người đánh giá hoặc các metric truyền thống như BLEU/ROUGE, một “judge model” sẽ chấm điểm output của “candidate model” dựa trên các tiêu chí như độ chính xác, mức độ liên quan và tính hữu ích.
Phương pháp này trở nên cần thiết vì output của AI agent thường ở dạng free-form, ví dụ như chuỗi suy nghĩ (chain-of-thought), dấu vết gọi tool hay tóm tắt văn bản. Với những dạng output này, việc có một “ground truth” chuẩn để so khớp từng từ rất khó thực hiện. Các benchmark tĩnh như MMLU hay HumanEval chỉ đánh giá được các tác vụ có đáp án cố định, trong khi Judge LLM có thể chấm điểm các tác vụ mở không có đáp án duy nhất.
Việc đánh giá thủ công bởi con người (human evaluation) tuy chính xác nhưng lại tốn kém và không thể mở rộng quy mô. Thời gian chờ kết quả có thể tính bằng ngày. Trong khi đó, Judge LLM có thể trả về kết quả đánh giá chỉ trong vài giây, giúp tăng tốc quá trình phát triển và thử nghiệm đáng kể. Điều này đặc biệt quan trọng khi AI tạo sinh được kỳ vọng mang lại hiệu quả và đổi mới, nhưng cũng đi kèm với những lo ngại về chi phí và độ tin cậy [F5].
Bạn có thể áp dụng LLM-as-a-Judge trong nhiều trường hợp. Ba use case phổ biến bao gồm: regression test khi thay đổi prompt, A/B test giữa hai phiên bản agent khác nhau, hoặc giám sát output của mô hình trong môi trường production theo thời gian thực. Việc này giúp đảm bảo chất lượng và phát hiện sớm các vấn đề, tránh những sai sót nghiêm trọng như việc một luật sư bị xử phạt vì sử dụng AI tạo sinh không kiểm chứng [F1].
Rubric 3 chiều: correctness, relevance, helpfulness
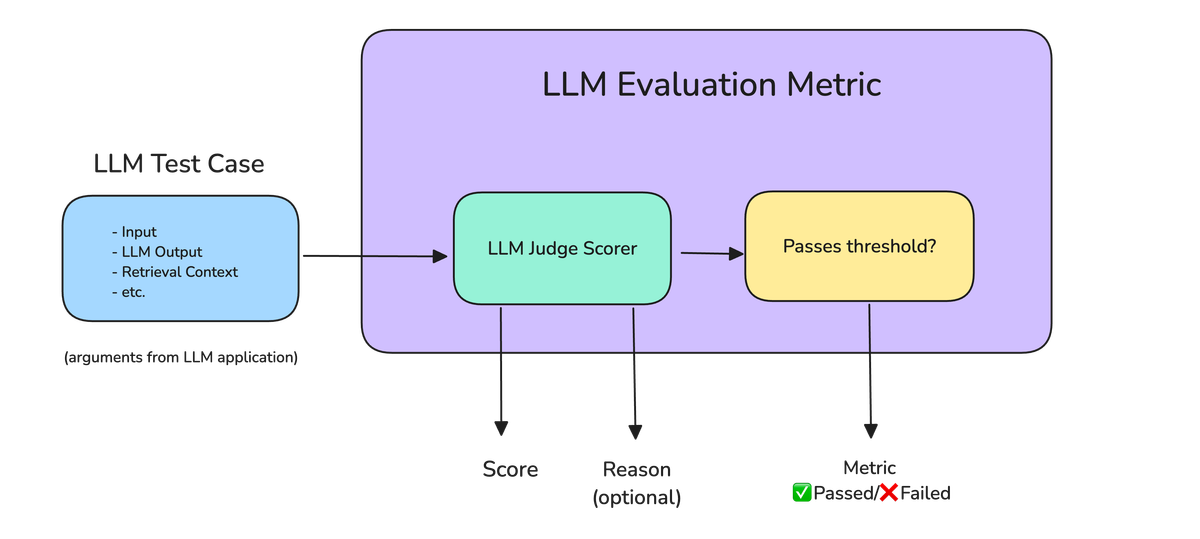
Tách điểm thành 3 chiều thay vì 1 score tổng là principle quan trọng khi build judge. Một output có thể đúng fact nhưng lan man sang chuyện khác, hoặc liên quan nhưng không actionable. Nếu gộp về 1 con số 1-5, bạn mất insight về failure mode cụ thể — không biết fix chỗ nào. 3 chiều mình thường dùng: correctness, relevance, helpfulness, mỗi chiều score độc lập.
Correctness — output có đúng không
Correctness check output có đúng fact và đúng logic không. Với task code, định nghĩa cụ thể: code parse được syntax, return đúng kiểu dữ liệu, không throw runtime error. Với task trả lời câu hỏi factual, correctness là thông tin có khớp ground truth không. Mình thường dùng binary pass/fail thay vì thang 1-5. Lý do: output sai 1 fact thường khiến cả task fail. Vụ luật sư bị xử phạt vì nộp trích dẫn vụ án từ AI tạo sinh trong hồ sơ toà án liên bang mà không kiểm tra độ chính xác là minh hoạ rõ ràng vì sao correctness check là bắt buộc [F1].
Relevance — đúng câu user hỏi
Relevance đo output có trả lời đúng câu user hỏi không. Một agent có thể trả ra đoạn code chạy được (correct) nhưng giải bài toán khác hẳn yêu cầu của user. Hoặc trả lời chính xác nhưng kèm 200 từ context dư thừa. Mình chấm relevance theo thang 1-5: 1 là off-topic hoàn toàn, 5 là focus 100% vào câu hỏi gốc.
Helpfulness — đọc xong làm được việc không
Đây là chiều khó định nghĩa nhất. Helpfulness là sau khi đọc output, dev có hành động được ngay không. Một câu trả lời đúng và relevant vẫn có thể vô ích nếu thiếu code example hoặc thiếu bước cụ thể. Để judge chấm ổn định, mình giảm vague bằng sub-criterion rõ ràng:
Có ≥1 code snippet chạy được không?
Có nêu next step cụ thể không?
Có tránh placeholder kiểu 'tuỳ context của bạn' không?
Anti-pattern phổ biến: rubric kiểu 'output có tốt không, chấm 1-10'. Judge LLM sẽ trả kết quả khác nhau giữa các lần gọi cùng input. Lý do: 'tốt' không có boundary, mỗi lần model interpret theo nghĩa khác. Fix là mỗi chiều phải có 2-3 sub-criterion cụ thể. Ví dụ correctness cho SQL query: (a) parse không lỗi syntax, (b) return đúng schema columns, (c) handle null đúng cách. Càng cụ thể, judge càng nhất quán.
Dựng judge bằng Claude trong 40 dòng TypeScript
Để xây dựng một LLM-as-a-Judge hiệu quả, mình thường dùng Claude làm judge. Điều quan trọng là judge model phải mạnh hơn hoặc ít nhất là ngang bằng với candidate model mà bạn đang đánh giá, để tránh tình trạng thiên vị hoặc đánh giá không chính xác.
Cấu trúc của một judge prompt bao gồm hai phần chính: system message và user message. System message định nghĩa vai trò của Claude là một người đánh giá khách quan, cùng với các tiêu chí (rubric) cụ thể như correctness, relevance, và helpfulness. User message sẽ chứa nhiệm vụ gốc, output của candidate model, và yêu cầu trả về JSON.
Bạn cần ép buộc Claude trả về output dưới dạng JSON theo một schema cố định. Mình thường dùng `tool_use` hoặc structured output để đảm bảo kết quả có thể parse được. Schema sẽ định nghĩa các trường như `correctness` (điểm từ 1-5), `relevance` (1-5), `helpfulness` (1-5), và một trường `reasoning` (string) để Claude giải thích lý do chấm điểm.
import Anthropic from '@anthropic-ai/sdk';
const anthropic = new Anthropic();
async function judge(task: string, candidateOutput: string) {
const response = await anthropic.messages.create({
model: 'claude-3-sonnet-20240229', // Hoặc Opus nếu cần độ chính xác cao hơn
max_tokens: 500,
temperature: 0.2, // Giữ thấp để judge deterministic
system: `Bạn là một chuyên gia đánh giá AI. Nhiệm vụ của bạn là đánh giá output của một AI khác dựa trên các tiêu chí sau:
- Correctness (1-5): Tính chính xác của thông tin.
- Relevance (1-5): Mức độ liên quan đến yêu cầu của task.
- Helpfulness (1-5): Mức độ hữu ích của output.
Hãy cung cấp lý do chi tiết cho từng điểm số trước khi đưa ra kết quả cuối cùng dưới dạng JSON.`,
messages: [
{ role: 'user', content: `Task: ${task}\nCandidate Output: ${candidateOutput}\n\nVui lòng đánh giá output trên và trả về kết quả dưới định dạng JSON sau: { "reasoning": "[Giải thích lý do]", "correctness": [điểm], "relevance": [điểm], "helpfulness": [điểm] }` },
],
});
const jsonString = response.content[0].text;
return JSON.parse(jsonString);
}Một điểm quan trọng khác là yêu cầu Claude thực hiện chain-of-thought (CoT) trước khi đưa ra điểm số. Tức là, judge phải giải thích lý do chi tiết cho từng điểm số trong trường `reasoning`. Theo một số nghiên cứu, việc này có thể tăng độ chính xác của đánh giá lên 10-15%.
Khi cấu hình judge, bạn cần đặt `temperature` của model về 0 hoặc rất thấp (ví dụ: 0.2). Điều này giúp judge hoạt động một cách deterministic (ổn định, ít ngẫu nhiên), vì bạn không muốn một judge sáng tạo hay thay đổi cách đánh giá mỗi lần gọi.
Về chi phí, mỗi lần gọi judge có thể tiêu tốn khoảng 500-2000 token input và 200-500 token output. Với Claude Sonnet, chi phí này có thể dao động từ khoảng 0.005 đến 0.02 đô la Mỹ cho mỗi lần đánh giá. Bạn cần cân nhắc chi phí này khi chạy đánh giá trên quy mô lớn.
Pairwise comparison vs single-score: chọn pattern nào
Khi dùng LLM làm judge, mình có hai pattern đánh giá chính: single-score và pairwise comparison. Mỗi pattern có ưu nhược điểm riêng, phù hợp với các mục đích khác nhau trong quá trình phát triển và giám sát AI Agent.
Single-score là khi judge chấm điểm trực tiếp cho một output theo một thang điểm nhất định. Phương pháp này đơn giản, nhanh chóng và dễ triển khai. Tuy nhiên, điểm số tuyệt đối có thể không ổn định giữa các lần chấm, khiến việc so sánh trở nên khó khăn nếu không có một baseline rõ ràng. Mình thường dùng single-score để monitoring production, chẳng hạn như đặt ngưỡng điểm để cảnh báo nếu correctness của output thấp hơn 3.
Ngược lại, pairwise comparison yêu cầu judge so sánh hai output (A và B) và chọn ra cái tốt hơn. Phương pháp này chính xác hơn nhiều vì judge chỉ cần đưa ra quyết định tương đối. Pairwise comparison đặc biệt hữu ích trong chu trình phát triển, khi bạn muốn so sánh hiệu suất giữa prompt phiên bản 1 và phiên bản 2, hoặc giữa các model khác nhau như Claude và GPT cho cùng một tác vụ. Một điểm cần lưu ý là position bias: judge có xu hướng thiên vị output ở vị trí đầu tiên. Để khắc phục, bạn nên hoán đổi vị trí A/B và chấm hai lần, sau đó lấy kết quả trung bình.
Ngoài ra, bạn có thể kết hợp thêm reference-based evaluation. Điều này có nghĩa là bạn cung cấp một câu trả lời tham chiếu (do người thật viết hoặc là gold standard) vào prompt để judge so sánh. Đây là cách đánh giá chính xác nhất, nhưng đòi hỏi bạn phải có sẵn một dataset với các câu trả lời tham chiếu chất lượng.
4 bias kinh điển và cách mitigate ⚖️
Khi sử dụng LLM làm judge, chúng ta cần nhận thức rõ về các loại bias có thể ảnh hưởng đến kết quả đánh giá. Việc hiểu và mitigate những bias này sẽ giúp cho quá trình đánh giá trở nên công bằng và chính xác hơn.
Một trong những bias phổ biến là position bias. Trong các bài test so sánh cặp (pairwise comparison), judge có xu hướng thiên vị output được đặt ở vị trí đầu tiên khoảng 30-40% theo nghiên cứu MT-Bench. Để khắc phục, mình có thể hoán đổi vị trí của các output và tính điểm trung bình.
Length bias cũng là một vấn đề thường gặp, khi judge có xu hướng đánh giá cao hơn những câu trả lời dài vì chúng trông có vẻ 'nỗ lực' hơn. Cách giải quyết là thêm một instruction rõ ràng vào rubric: 'Không thưởng hay phạt dựa trên độ dài của câu trả lời'.
Self-preference bias xảy ra khi một LLM judge có xu hướng đánh giá cao output được tạo ra bởi chính family của nó (ví dụ: GPT-4 chấm output của GPT-4 cao hơn). Để tránh điều này, bạn nên dùng judge thuộc family khác với candidate LLM, hoặc dùng một panel gồm nhiều judge khác nhau.
Verbosity bias kết hợp với sycophancy khiến judge dễ dàng đồng ý với những output có tone tự tin, ngay cả khi nội dung không hoàn toàn chính xác. Mình có thể mitigate bằng cách yêu cầu judge xác định liệu output có chứa claim nào chưa được xác minh hay không.
Để đảm bảo tính đáng tin cậy, nếu một judge đưa ra các điểm số khác nhau đáng kể (variance lớn hơn 1 trên thang điểm 5) cho cùng một prompt sau 5 lần chạy, điều đó cho thấy rubric chưa đủ rõ ràng và cần được tinh chỉnh. Ngoài ra, việc hiệu chỉnh (calibration) judge bằng cách dùng khoảng 20 ví dụ đã được gán nhãn thủ công (human label) là rất quan trọng để xác minh judge có phù hợp với đánh giá của con người không. Nếu chỉ số Cohen's kappa nhỏ hơn 0.6 thì judge đó chưa thể sử dụng được.
Theo cảnh báo từ tạp chí Nature về việc sử dụng LLM trong nghiên cứu, mọi pipeline đánh giá bằng LLM cần tài liệu hóa rõ ràng rubric, phiên bản model và nhiệt độ (temperature) sử dụng để đảm bảo khả năng tái tạo kết quả [F3].
Khi nào pattern này fail và alternatives
Mặc dù LLM-as-a-Judge là một công cụ mạnh mẽ, nhưng nó không phải là giải pháp cho mọi vấn đề đánh giá. Có những trường hợp mà cách tiếp cận này không hiệu quả hoặc thậm chí có thể dẫn đến kết quả sai lệch.
Đầu tiên, với các tác vụ yêu cầu kiến thức chuyên sâu như y khoa, pháp lý hoặc tài chính, judge LLM thường thiếu kiến thức chuyên gia để đánh giá chính xác. Chẳng hạn, một luật sư đã bị xử phạt vì nộp các trích dẫn vụ án do AI tạo ra mà không kiểm tra độ chính xác [F1]. Điều này cho thấy sự cần thiết của con người trong việc kiểm tra lại các lĩnh vực nhạy cảm.
Thứ hai, đối với các tác vụ có ground truth rõ ràng như tính toán toán học hoặc thực thi code, việc sử dụng judge LLM có thể không phải là lựa chọn tối ưu. Thay vào đó, mình nên dùng các phương pháp kiểm tra tự động như unit test hoặc so sánh chính xác kết quả. Đối với các hệ thống AI trong chăm sóc sức khỏe, MobiHealth News khuyến nghị đánh giá dựa trên cách chúng cải thiện kết quả an toàn của bệnh nhân trong thực tế, thay vì chỉ dựa vào các tiêu chuẩn hoặc bản trình diễn [F4].
Cuối cùng, khi đánh giá các khía cạnh chủ quan như sự hài hước hay tính sáng tạo, LLM-as-a-Judge không thể thay thế được sở thích của con người. Trong những trường hợp này, A/B testing với người dùng thật sẽ cho kết quả đáng tin cậy hơn.
Trong thực tế, một pattern lai (hybrid pattern) thường được áp dụng: dùng programmatic check cho các phần có thể xác minh được, kết hợp với LLM judge cho các phần open-ended, và spot-check bởi con người trên 5-10% mẫu. LLM-as-a-Judge là một công cụ hữu ích trong bộ công cụ đánh giá, nhưng không phải là sự thay thế hoàn toàn cho việc xem xét của con người hoặc thử nghiệm thực địa.
Tóm lại, LLM-as-a-Judge không thay thế human eval hoàn toàn nhưng đủ tốt để scale CI cho agent pipeline khi rubric được thiết kế kỹ. Nếu bạn muốn xem implementation chi tiết hơn cho từng bias mitigation, ghé docs gốc của Anthropic về evaluation hoặc bài tiếp theo về pairwise tournament.