
RAG cho Agent: tích hợp knowledge base để agent biết thêm domain riêng
Người học xây RAG pipeline hoàn chỉnh: chunking, embedding, lưu vector store (ChromaDB/FAISS), viết retrieval tool cho agent gọi. Agent dùng retrieved
Agent của bạn trả lời sai khi hỏi về tài liệu nội bộ công ty? Đó là vì LLM không biết domain riêng của bạn — và RAG truyền thống kiểu top-k rồi nhồi vào prompt đã chạm trần độ chính xác trong môi trường doanh nghiệp. Bài này mình đi qua kiến trúc Agentic RAG 3 thành phần (retrieval tool, answer synthesis, self-evaluation), cách dựng knowledge base với ChromaDB trong Python, và đóng gói logic truy vấn thành tool để agent tự quyết định khi nào gọi.
Tại sao RAG "truyền thống" là chưa đủ cho Agent? 🤔
RAG truyền thống, hay còn gọi là Vanilla RAG, là một kỹ thuật quen thuộc trong việc giúp các mô hình ngôn ngữ lớn (LLM) truy cập thông tin bên ngoài. Về cơ bản, nó hoạt động bằng cách tìm kiếm top-k tài liệu có liên quan nhất từ một kho dữ liệu, sau đó nhồi chúng vào ngữ cảnh của LLM để sinh câu trả lời.
Tuy nhiên, phương pháp RAG "tĩnh" này đang dần bộc lộ nhược điểm, đặc biệt trong môi trường doanh nghiệp. Nó hoạt động như một pipeline cố định: truy vấn, lấy tài liệu, và tạo phản hồi. Agent không có quyền tự chủ để quyết định khi nào cần tìm kiếm, tìm kiếm cái gì, hay xử lý kết quả như thế nào. Điều này khiến RAG truyền thống khó xử lý các tác vụ phức tạp, đòi hỏi nhiều bước truy vấn hoặc khả năng tự đánh giá thông tin.
Đây là lúc khái niệm Agentic RAG xuất hiện, đại diện cho một bước tiến quan trọng. Thay vì chỉ là một pipeline thụ động, Agentic RAG cho phép agent chủ động tương tác với knowledge base. Agent có thể tự quyết định khi nào cần truy vấn, tìm kiếm thông tin gì, và quan trọng nhất là làm gì với những kết quả nhận được [F1]. Ví dụ, các kiến trúc như Corrective RAG (CRAG) sử dụng một mô hình đánh giá nhẹ để kiểm tra tài liệu retrieved, và nếu không phù hợp, agent sẽ tự động kích hoạt các cơ chế fallback như tìm kiếm web hoặc viết lại truy vấn [F2].
Trong các ứng dụng doanh nghiệp đòi hỏi độ chính xác và linh hoạt cao, Agentic RAG đang dần thay thế các hệ thống RAG tĩnh [F1]. Một mô hình kiến trúc RAG agent đáng tin cậy thường bao gồm ba thành phần chính: một công cụ truy xuất (retrieval tool), một bộ tổng hợp câu trả lời (answer synthesis) và khả năng tự đánh giá (self-evaluation) chất lượng đầu ra [F3]. Điều này giúp agent không chỉ tìm kiếm mà còn hiểu và sử dụng thông tin một cách thông minh hơn.
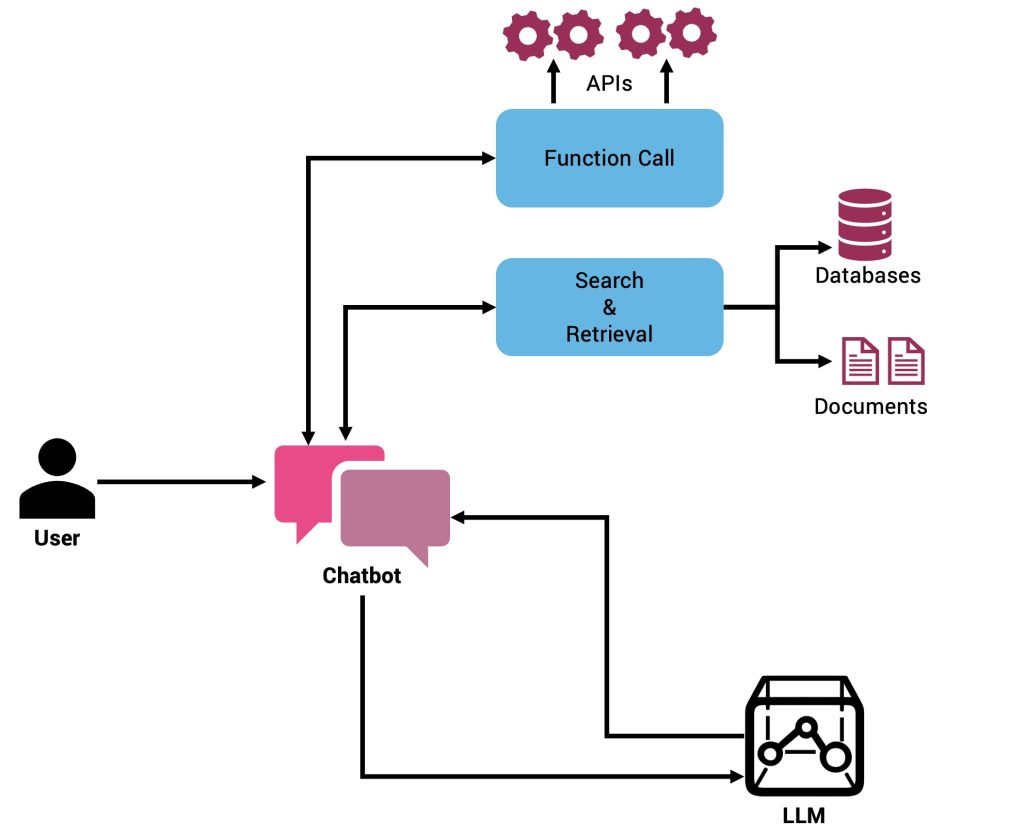
Kiến trúc của một hệ thống Agentic RAG 🏗️
Khi build agent có domain knowledge riêng, một pattern đáng tin cậy gồm 3 thành phần cốt lõi: retrieval tool, answer synthesis, và self-evaluation [F3]. Đây không phải pipeline tuần tự cứng nhắc như vanilla RAG, mà là một vòng lặp có agent đứng giữa điều phối. Agent tự quyết định khi nào cần truy vấn, truy vấn bao nhiêu lần, và có nên tin kết quả không [F1].
3 thành phần và vai trò
Retrieval Tool không chỉ là một hàm `search(query)` ẩn dưới capo. Nó được expose ra cho agent dưới dạng tool có description rõ ràng — tên, mô tả input/output, khi nào nên gọi. Agent đọc description đó để quyết định có gọi tool không, thay vì developer hardcode bước retrieval ở đầu pipeline. Vector store như ChromaDB là lựa chọn phổ biến cho phần này [F4].
Answer Synthesis là bước LLM nhận evidence từ tool và tổng hợp thành câu trả lời dựa trên dữ liệu đó [F3]. Khác biệt quan trọng so với extractive QA: agent không lặp lại nguyên văn document, mà diễn giải, kết hợp nhiều đoạn evidence, và format theo ý đồ câu hỏi. Nếu evidence không đủ, agent có thể quyết định gọi retrieval lần nữa với query khác.
Self-Evaluation là phần phân biệt agentic RAG với RAG cơ bản. Agent tự chấm điểm câu trả lời mình vừa sinh ra dựa trên evidence đã retrieve [F3]. Nếu điểm thấp — ví dụ evidence không support claim, hoặc câu trả lời lệch khỏi context — agent có thể retry hoặc fallback. Pattern Corrective RAG đi xa hơn: chèn evaluator model nhẹ giữa retriever và generator, và nếu document bị đánh giá Incorrect thì kích hoạt fallback như web search hoặc rewrite query trước khi sinh câu trả lời [F2].
Luồng hoạt động end-to-end
User gửi query → agent phân tích intent, xác định có cần domain knowledge không.
Nếu cần, agent gọi Retrieval Tool với query đã reformulate (không nhất thiết giống query gốc).
Tool query vector DB, trả về top-k chunks kèm metadata.
Agent đọc evidence, tổng hợp thành draft answer.
Self-evaluation: agent (hoặc evaluator riêng) chấm điểm answer vs evidence.
Nếu pass → trả về user. Nếu fail → retry với query mới hoặc fallback source.
Điểm khác biệt đáng chú ý: agent có quyền không gọi retrieval nếu thấy không cần. Câu hỏi kiểu "hello" hay "viết hộ mình regex email" không động vào knowledge base. Đây là lý do agentic RAG tiết kiệm token hơn vanilla RAG ở traffic thực tế — không phải query nào cũng đáng truy vấn vector DB.
Step 1: Xây dựng Knowledge Base với Python và ChromaDB 📚
Để agent có thể truy vấn thông tin chuyên biệt, chúng ta cần xây dựng một Knowledge Base (KB). Đây là nơi lưu trữ các tài liệu nội bộ, đã được xử lý để LLM dễ dàng hiểu và sử dụng. Mình sẽ hướng dẫn bạn cách tạo KB bằng Python và ChromaDB, một vector store phổ biến cho RAG trên tài liệu riêng tư [F4].
Chuẩn bị dữ liệu và Ingestion
Đầu tiên, bạn cần có dữ liệu nguồn. Mình sẽ dùng một vài file Markdown (.md) giả định chứa các chính sách nội bộ của công ty. Bạn có thể thay thế bằng bất kỳ định dạng tài liệu nào khác như PDF, DOCX, CSV. Sau đó, chúng ta sẽ dùng thư viện LlamaIndex hoặc LangChain để tải và xử lý tài liệu.
Quá trình ingestion bao gồm tải tài liệu và chia nhỏ (chunking) chúng. Chunking là bước quan trọng: chia tài liệu dài thành các đoạn nhỏ hơn. Kích thước chunk (chunk size) và mức độ chồng lấn (overlap) giữa các chunk ảnh hưởng trực tiếp đến chất lượng truy vấn. Chunk quá lớn có thể chứa nhiều thông tin không liên quan, chunk quá nhỏ có thể làm mất ngữ cảnh. Overlap giúp duy trì ngữ cảnh khi chia tách.
from llama_index.readers.file import SimpleDirectoryReader
from llama_index.node_parser import SentenceSplitter
# Tải tài liệu từ thư mục 'data'
documents = SimpleDirectoryReader(input_dir="./data").load_data()
# Chia tài liệu thành các chunk
# chunk_size và chunk_overlap cần được tinh chỉnh dựa trên loại dữ liệu của bạn
parser = SentenceSplitter(chunk_size=512, chunk_overlap=20)
nodes = parser.get_nodes_from_documents(documents)
print(f"Đã tải {len(documents)} tài liệu và tạo {len(nodes)} chunk.")Embedding và Lưu trữ vào ChromaDB
Sau khi có các chunk, chúng ta cần chuyển chúng thành các vector số học (embedding). Các vector này biểu diễn ngữ nghĩa của từng chunk. Mình sẽ dùng mô hình embedding. Bạn có thể chọn `sentence-transformers` cho các dự án local hoặc dùng API của OpenAI với `text-embedding-3-small` để có kết quả tốt hơn.
import chromadb
from chromadb.utils import embedding_functions
# Khởi tạo ChromaDB client (persistent client để lưu trữ trên đĩa)
client = chromadb.PersistentClient(path="./chroma_db")
# Chọn embedding function
# Dùng sentence-transformers cho local hoặc OpenAIEmbeddingFunction cho API
# from llama_index.embeddings.openai import OpenAIEmbedding
# embed_model = OpenAIEmbedding(model="text-embedding-3-small")
# Ví dụ dùng sentence-transformers (cần cài đặt 'sentence-transformers')
embedding_function = embedding_functions.SentenceTransformerEmbeddingFunction(model_name="all-MiniLM-L6-v2")
# Tạo hoặc lấy collection
collection_name = "company_policies"
collection = client.get_or_create_collection(name=collection_name, embedding_function=embedding_function)
# Thêm các node (chunk) vào collection
# Mỗi node sẽ được chuyển thành embedding và lưu trữ cùng với metadata
for i, node in enumerate(nodes):
collection.add(
documents=[node.text],
metadatas=[node.metadata],
ids=[f"doc_{i}"]
)
print(f"Đã thêm {collection.count()} chunk vào ChromaDB collection '{collection_name}'.")Kiểm tra Knowledge Base
Để đảm bảo dữ liệu đã được lưu trữ thành công, chúng ta có thể thực hiện một truy vấn đơn giản trực tiếp trên ChromaDB. Truy vấn này sẽ tìm kiếm các chunk có ngữ nghĩa tương đồng với câu hỏi của bạn.
# Thực hiện truy vấn để kiểm tra
query_text = "Chính sách nghỉ phép của công ty là gì?"
results = collection.query(
query_texts=[query_text],
n_results=2
)
print("\nKết quả truy vấn thử nghiệm:")
for doc in results['documents'][0]:
print(f"- {doc}")Nếu bạn thấy các đoạn văn bản liên quan đến chính sách nghỉ phép, điều đó có nghĩa là Knowledge Base của bạn đã được thiết lập thành công. ChromaDB là lựa chọn tốt cho RAG khi cần tìm kiếm tài liệu riêng tư và có thể kết hợp với memory layer để agent ghi nhớ ngữ cảnh từ các phiên truy vấn trước [F4].
Step 2: Đóng gói logic truy vấn thành một Tool cho Agent 🔧
Agent không gọi trực tiếp ChromaDB. Nó cần một tool — một function với input/output rõ ràng, kèm mô tả để LLM biết khi nào nên kích hoạt. Pattern khuyến nghị cho RAG agent đáng tin cậy gồm 3 thành phần: retrieval tool, answer synthesis và self-evaluation [F3]. Section này mình đóng gói bước retrieval thành tool đầu tiên — chính là 'cánh tay' để agent với tới knowledge base. Agent sẽ tự quyết định khi nào dùng và query gì.
from chromadb import PersistentClient
from openai import OpenAI
client = OpenAI()
chroma = PersistentClient(path="./chroma_db")
collection = chroma.get_collection("internal_docs")
def retrieve_internal_documents(query: str, top_k: int = 5) -> list[dict]:
"""
Tìm tài liệu nội bộ liên quan tới câu hỏi của user.
DÙNG tool này KHI: user hỏi về policy công ty, quy trình nội bộ,
tài liệu kỹ thuật của team, hoặc thông tin không có trên public web.
KHÔNG dùng KHI: user chat thông thường, hỏi kiến thức general
(toán, lịch sử), hoặc câu hỏi về public library docs.
Args:
query: Câu hỏi natural language (VN hoặc EN).
VD: "policy nghỉ phép", "quy trình deploy staging".
top_k: Số document trả về (default 5, max 10).
Returns:
List dict, mỗi dict gồm:
- source: tên file gốc
- content: nội dung chunk (200-500 từ)
- score: độ liên quan (0-1, cao hơn = liên quan hơn)
"""
embedding = client.embeddings.create(
input=query,
model="text-embedding-3-small",
).data[0].embedding
results = collection.query(
query_embeddings=[embedding],
n_results=top_k,
)
return [
{
"source": meta["source"],
"content": doc,
"score": round(1 - dist, 3),
}
for doc, meta, dist in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0],
)
]Docstring không phải viết cho bạn đọc — nó là 'spec' cho LLM. Khi agent framework (LangChain, LlamaIndex, hoặc tự code function-calling) convert function này thành tool, nó parse docstring và inject thẳng vào system prompt. LLM dựa vào phần 'DÙNG khi / KHÔNG dùng khi' để quyết định gọi hay bỏ qua. Thiếu docstring chi tiết, agent sẽ gọi retrieve cho cả câu 'hello bạn khoẻ không' — vừa tốn token vừa nhiễu context window.
Format return mình cố tình giữ flat: 3 field source, content, score. Không nest dict sâu, không trả raw ChromaDB response (có nhiều field thừa như embedding vector 1536 chiều). LLM downstream chỉ cần ngần đó để cite nguồn và đánh giá độ tin. Nếu sau này bạn add self-evaluation step (component thứ 3 trong pattern [F3]) thì có thể thêm field `chunk_id` để evaluator chấm lại từng chunk thay vì cả block response.
Một lưu ý dễ miss: ChromaDB trả về distance (càng nhỏ càng giống), không phải similarity score. Mình convert `1 - dist` cho intuitive, nhưng công thức này chỉ đúng khi metric là cosine và embedding đã normalize. Default của Chroma là `l2`, nên nếu bạn không set metric lúc tạo collection thì score có thể âm hoặc >1. Check `collection.metadata` để confirm, hoặc tạo collection với `metadata={"hnsw:space": "cosine"}` cho chắc.
Cách triển khai trong dự án thực tế
Trong các dự án thực tế, RAG cơ bản dùng top-k retrieval rồi nhồi vào prompt đã chạm trần về độ chính xác trong môi trường doanh nghiệp [F1]. Xu hướng hiện tại là chuyển sang agentic RAG, nơi agent tự quyết định khi nào truy vấn knowledge base, truy vấn nhiều lần và tự đánh giá kết quả [F1].
Một kiến trúc RAG agent đáng tin cậy thường có 3 thành phần chính: retrieval tool để truy hồi thông tin từ vector store, answer synthesis để LLM tổng hợp câu trả lời dựa trên evidence, và self-evaluation để agent tự chấm điểm chất lượng đầu ra [F3]. Đây là một pattern được khuyến nghị khi mình build agent có domain knowledge riêng [F3].
Corrective RAG (CRAG) là một phương pháp triển khai cụ thể, chèn một evaluator model nhẹ giữa retriever và generator [F2]. Nếu evaluator đánh giá tài liệu retrieved là không chính xác, hệ thống sẽ tự động kích hoạt fallback (ví dụ như web search hoặc rewrite query) trước khi để LLM sinh câu trả lời [F2].
Khi chọn công cụ, ChromaDB là một vector store phổ biến cho các ứng dụng RAG tìm kiếm tài liệu riêng tư bằng Python [F4]. Mình có thể kết hợp nó với một memory layer để agent ghi nhớ ngữ cảnh của các phiên truy vấn trước đó [F4]. Việc lựa chọn giữa RAG, fine-tuning hay prompting phụ thuộc vào bài toán cụ thể: RAG phù hợp khi knowledge thay đổi nhanh và cần truy vấn dữ liệu domain riêng [F5].
Tổng kết: agentic RAG khác vanilla RAG ở chỗ agent chủ động chọn khi nào retrieve và tự đánh giá kết quả, thay vì pipeline tuần tự cứng. Nếu bạn muốn xem code mẫu đầy đủ và phần demo retrieval tool chạy thực tế, video gốc trên kênh có walkthrough chi tiết hơn phần này.