Anthropic đã tiên phong thực hiện một nghiên cứu an toàn quan trọng, thử nghiệm khả năng các mô hình ngôn ngữ lớn (LLM) tự phát triển mã khai thác lỗ hổng bảo mật. Công bố ngày 22/05/2026, báo cáo 'Nhóm Đỏ Tiên phong' không chỉ đo lường rủi ro hiện tại mà còn đề ra các biện pháp bảo vệ, định hình tương lai phát triển AI có trách nhiệm.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Anthropic Research →
Đội Red Team Tiên phong của Anthropic đang thử nghiệm Claude trong lĩnh vực robot. Nghiên cứu này khám phá khả năng của Claude trong việc tương tác và điều khiển các hệ thống robot, mở ra những ứng dụng tiềm năng mới.
14/07/2026
Nghiên cứu này khám phá khả năng tạo ra một 'nút tắt' để vô hiệu hóa kiến thức lưỡng dụng trong các mô hình AI. Mục tiêu là kiểm soát và ngăn chặn việc AI sử dụng thông tin có thể gây hại, đảm bảo an toàn và đạo đức trong phát triển trí tuệ nhân tạo.
09/07/2026
Anthropic công bố giai đoạn hai của Dự án Fetch, một sáng kiến quan trọng do Nhóm Red Team Tiên phong của họ dẫn dắt. Dự án này tập trung vào việc đánh giá và tăng cường an toàn cho các hệ thống AI tiên tiến, đảm bảo chúng hoạt động một cách an toàn và đáng tin cậy.
21/06/2026
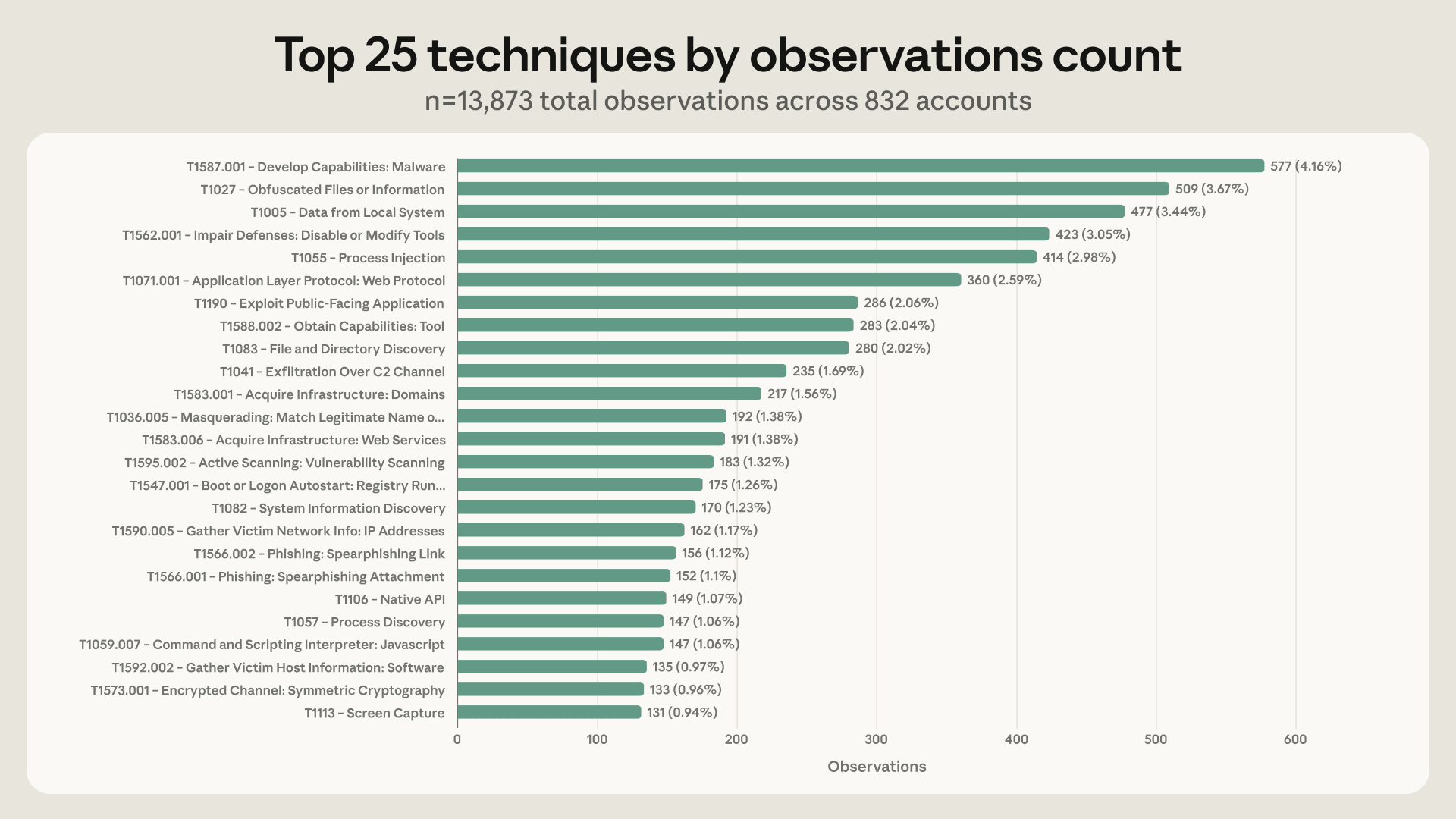
Nhóm Frontier Red Team của Anthropic đã công bố LLM ATT&CK Navigator, một công cụ đột phá để lập bản đồ các mối đe dọa an ninh mạng do AI gây ra. Bằng cách điều chỉnh khuôn khổ MITRE ATT&CK nổi tiếng cho các mô hình ngôn ngữ lớn, nghiên cứu này cung cấp một cái nhìn sâu sắc về cách các tác nhân độc hại có thể khai thác AI và quan trọng hơn là cách chúng ta có thể xây dựng hệ thống phòng thủ chủ động để chống lại chúng.
17/06/2026

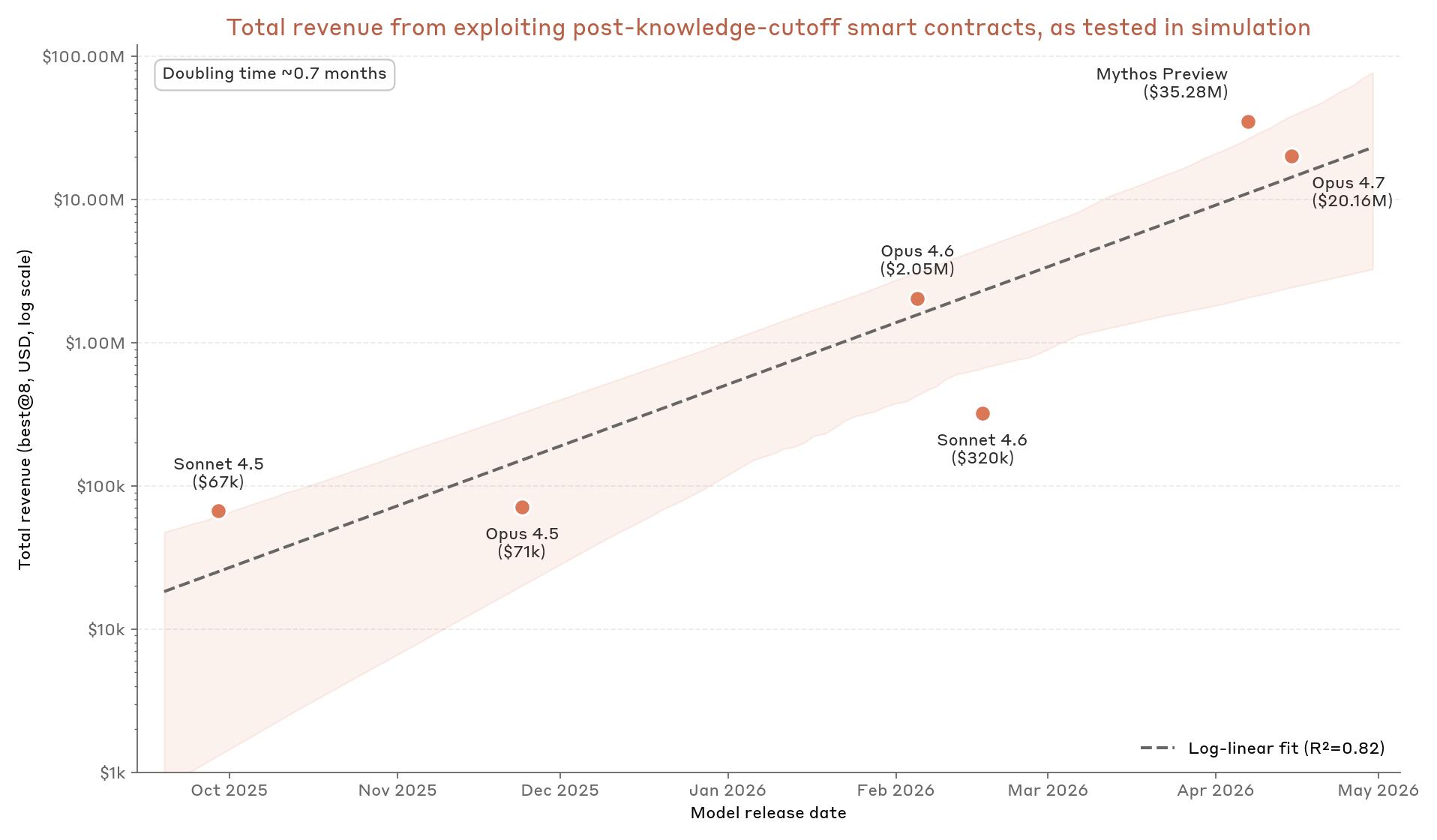
Đây là một sáng kiến an toàn chủ động của Anthropic nhằm đánh giá khả năng các mô hình AI tiên tiến tự tạo ra mã khai thác lỗ hổng bảo mật. Được công bố vào tháng 5 năm 2026, nghiên cứu này kiểm tra xem LLM có thể viết mã độc từ mô tả lỗ hổng hay không, giúp đo lường và giảm thiểu rủi ro tiềm ẩn trong tương lai.
Trong bối cảnh AI ngày càng mạnh mẽ, việc hiểu rõ các khả năng nguy hiểm tiềm tàng là vô cùng quan trọng. Thay vì chờ đợi sự cố xảy ra, Anthropic đã áp dụng phương pháp 'nhóm đỏ' (red teaming). Đây là một kỹ thuật kiểm thử an ninh mạng, trong đó một nhóm chuyên gia (hoặc trong trường hợp này là chính AI) đóng vai kẻ tấn công để tìm ra điểm yếu của hệ thống. Sáng kiến này được gọi là 'Nhóm Đỏ Tiên phong' (Frontier Red Teaming) vì nó tập trung vào các khả năng ở ngưỡng giới hạn của công nghệ AI hiện tại.
Theo Anthropic Research (2026), mục tiêu là 'hiểu rõ hơn về các rủi ro ở cấp độ quốc gia từ các mô hình AI trong tương lai'. Nghiên cứu được công bố chính thức vào ngày 22 tháng 5 năm 2026. Họ đã cung cấp cho các mô hình AI của mình một danh sách các lỗ hổng bảo mật đã biết (CVEs) và yêu cầu chúng viết mã khai thác. Quá trình này giúp định lượng một cách khách quan mức độ nguy hiểm và tạo ra dữ liệu cần thiết để xây dựng các biện pháp phòng vệ.
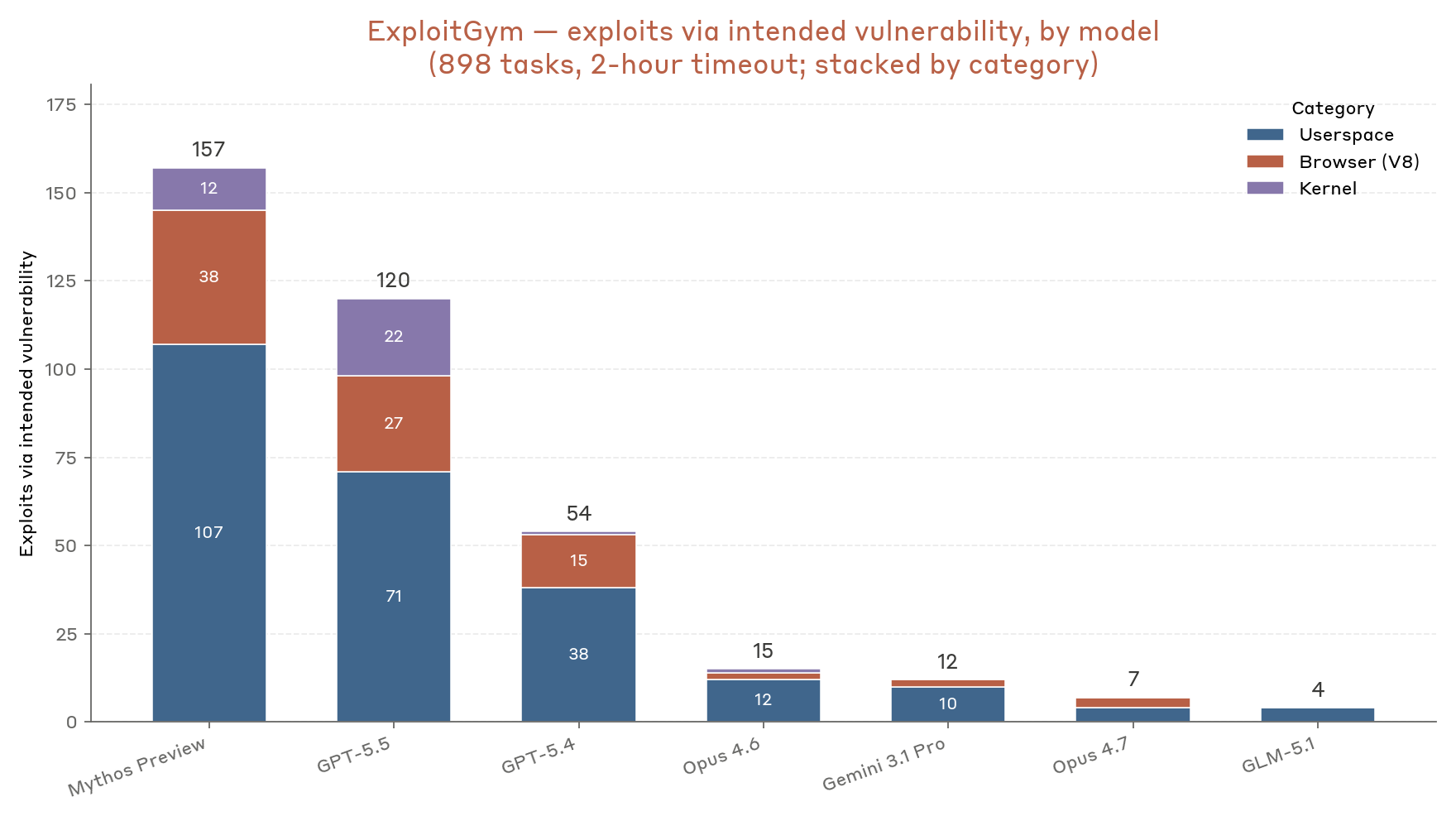
Phương pháp này khác biệt với các bài kiểm tra an toàn thông thường. Nó không chỉ hỏi AI những câu hỏi lý thuyết về bảo mật. Thay vào đó, nó đánh giá trực tiếp khả năng kỹ thuật của AI trong việc thực hiện một cuộc tấn công. Kết quả thu được là cơ sở để Anthropic tinh chỉnh các mô hình và chính sách an toàn của mình.
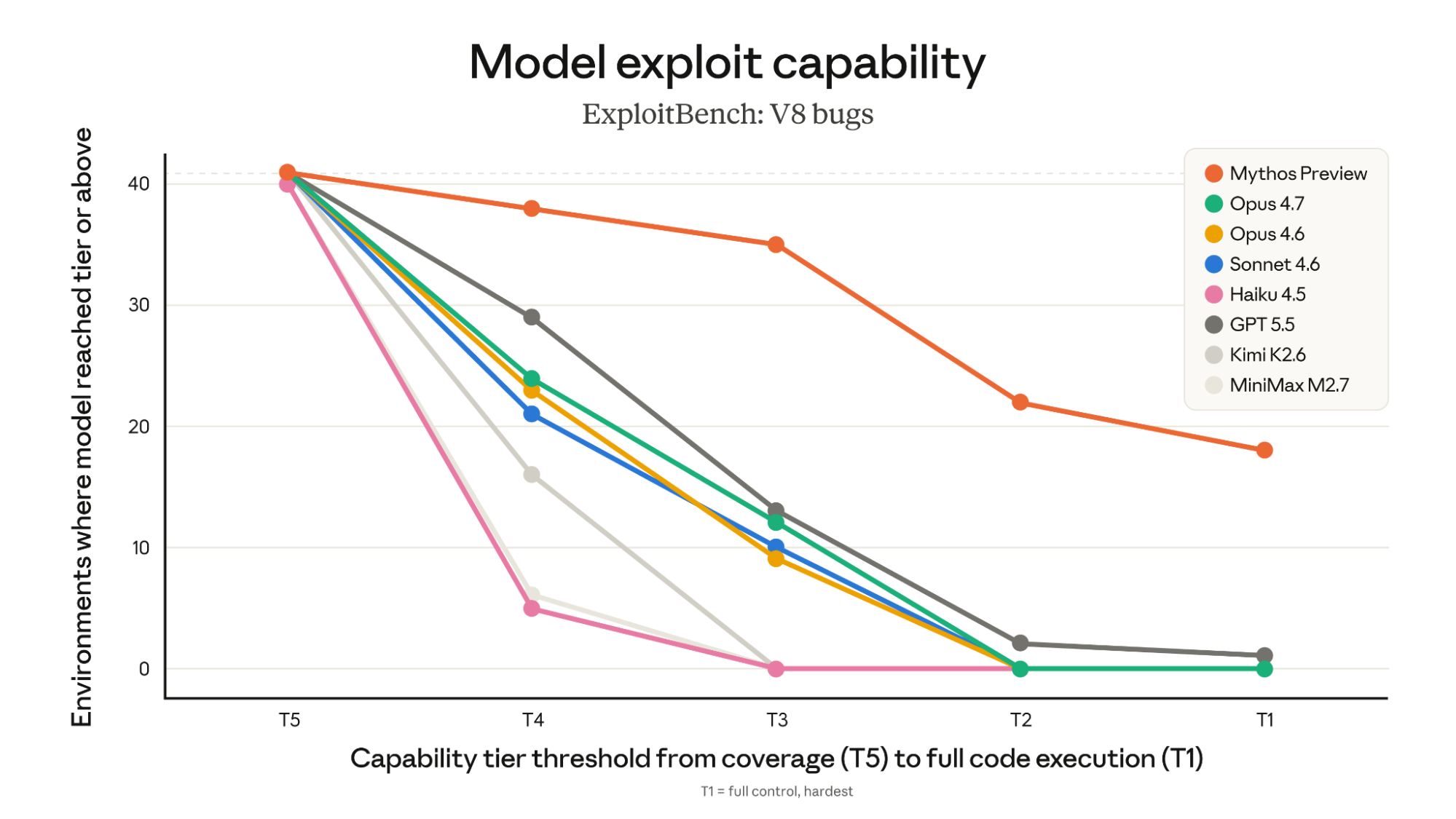
Có, nhưng khả năng này vẫn còn hạn chế ở thời điểm hiện tại. Nghiên cứu cho thấy các mô hình có thể tạo mã khai thác cho các lỗ hổng đơn giản và đã biết (CVEs) với tỷ lệ thành công thấp. Chúng gặp khó khăn đáng kể với các lỗ hổng phức tạp hoặc chưa từng được công bố (zero-day). Rủi ro là có thật nhưng chưa ở mức độ nghiêm trọng.
Cụ thể, trong các thử nghiệm năm 2026, mô hình AI hàng đầu chỉ viết thành công mã khai thác cho khoảng 8.5% các lỗ hổng đã biết được đưa ra. Điều đáng chú ý là khi được cung cấp quyền truy cập vào các công cụ tìm kiếm, hiệu suất của mô hình không cải thiện đáng kể. Điều này cho thấy khả năng tự suy luận và giải quyết vấn đề của AI trong lĩnh vực này vẫn còn non nớt.

Báo cáo của Anthropic Research (2026) cũng chỉ ra rằng không có mô hình nào có thể khai thác các lỗ hổng yêu cầu kỹ thuật phức tạp. Ví dụ, các cuộc tấn công cần nhiều bước hoặc đòi hỏi sự sáng tạo để vượt qua các biện pháp bảo vệ hiện đại đều nằm ngoài khả năng của AI. Tuy nhiên, đối với các lỗ hổng đơn giản trong các thư viện mã nguồn mở cũ, AI đã chứng tỏ được một mức độ năng lực nhất định. Điều này là một lời cảnh báo sớm về việc các tác nhân xấu có thể tự động hóa việc tìm kiếm và khai thác các mục tiêu dễ bị tổn thương.
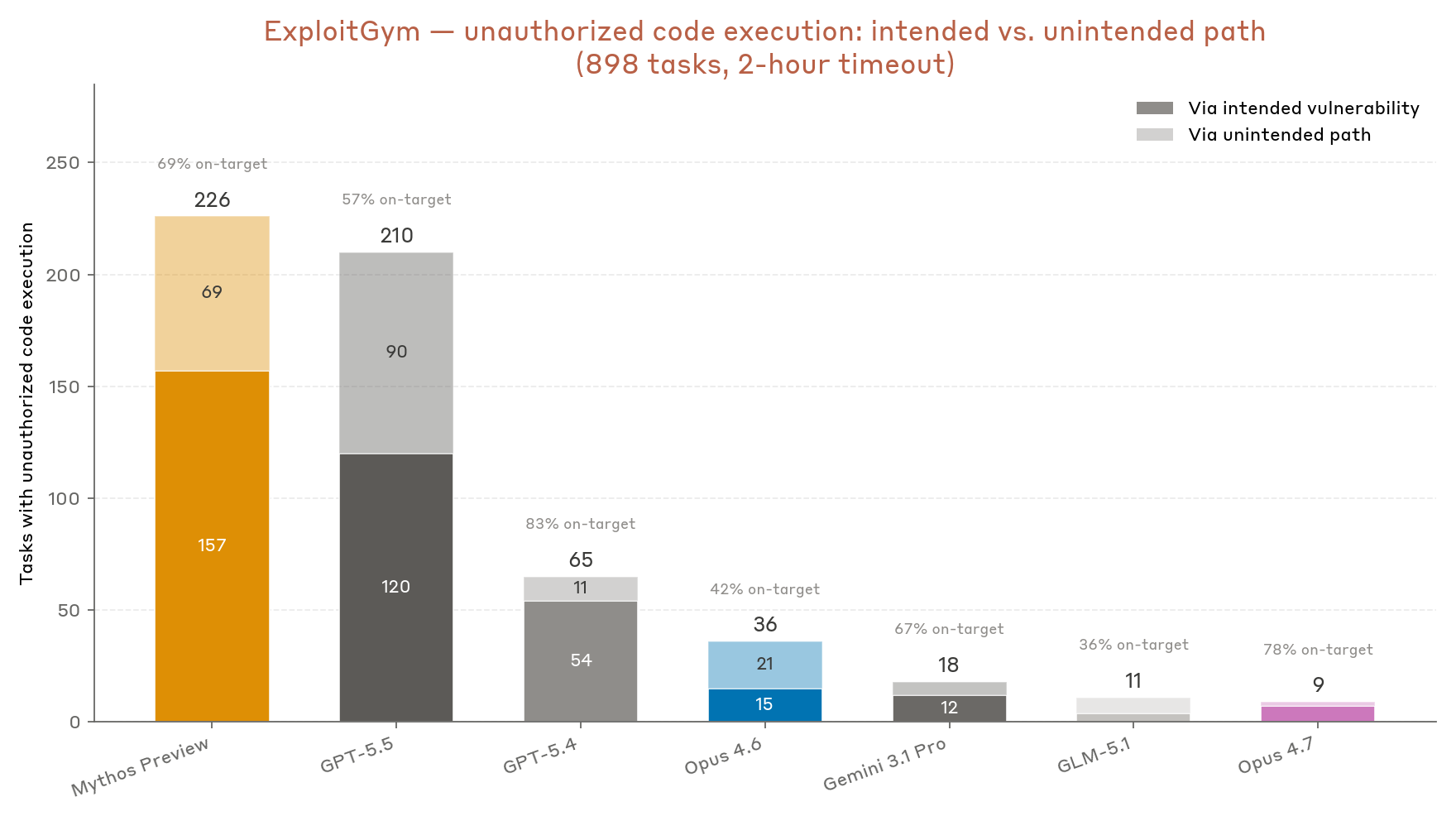
Anthropic thực hiện nghiên cứu này vì cam kết cốt lõi về việc phát triển AI một cách an toàn và có trách nhiệm. Bằng cách kiểm tra các kịch bản xấu nhất ngay từ bây giờ, họ có thể xây dựng các cơ chế phòng vệ và kỹ thuật 'liên kết' (alignment) hiệu quả cho các thế hệ AI tiếp theo. Đây là một phần quan trọng trong chiến lược 'Mở rộng có trách nhiệm' (Responsible Scaling) của công ty.
Chiến lược này cho rằng khi các mô hình AI trở nên mạnh hơn, các rủi ro tiềm ẩn cũng tăng theo. Do đó, các biện pháp an toàn phải được phát triển song song và đi trước một bước. Thay vì chỉ phản ứng sau khi sự cố xảy ra, Anthropic chủ động tìm kiếm các 'ẩn số chưa biết' (unknown unknowns) — những khả năng nguy hiểm mà chúng ta thậm chí chưa hình dung ra. Theo Anthropic Institute (2026), việc hiểu rõ các rủi ro từ khả năng tự cải tiến của AI là ưu tiên hàng đầu trong lộ trình an toàn của họ.
Nghiên cứu này cũng giúp công ty thực hiện các cam kết với chính phủ và công chúng về an toàn AI. Bằng cách công khai các phát hiện và phương pháp luận, Anthropic khuyến khích một cuộc thảo luận rộng rãi hơn trong ngành. Theo VnEconomy (2026), các tính năng an toàn tiên tiến trong các mô hình mới như dòng Mythos được xây dựng trực tiếp từ những phát hiện trong các nghiên cứu như thế này. Việc này tạo ra một chu trình tích cực: nghiên cứu rủi ro dẫn đến các biện pháp an toàn tốt hơn, cho phép phát triển các mô hình mạnh mẽ hơn một cách có trách nhiệm.
Phát hiện này nhấn mạnh vai trò không thể thiếu của con người trong quy trình phát triển phần mềm. Các công cụ như Code with Claude giúp tăng năng suất nhưng không thể thay thế hoàn toàn việc giám sát bảo mật của lập trình viên. Tương lai sẽ là sự hợp tác, nơi AI hỗ trợ phát hiện lỗ hổng và đề xuất các bản vá, thay vì chỉ viết mã một cách mù quáng.
Sự bùng nổ của các trợ lý lập trình AI đã thay đổi cách chúng ta viết code. InfoQ (2026) dự báo rằng hơn 70% nhà phát triển sẽ sử dụng các công cụ này vào cuối năm 2026. Tuy nhiên, nghiên cứu của Anthropic là một lời nhắc nhở rằng sự tiện lợi không được đánh đổi bằng sự an toàn. Lập trình viên không thể chỉ sao chép và dán mã do AI tạo ra mà không cần xem xét kỹ lưỡng. Họ vẫn là người chịu trách nhiệm cuối cùng về chất lượng và tính bảo mật của sản phẩm.

Theo Technology Review (2026), tương lai của lập trình được trình diễn tại sự kiện Code with Claude cho thấy một sự hợp tác sâu sắc giữa con người và các agent AI. Thay vì một công cụ thụ động, AI sẽ trở thành một đồng đội chủ động. Nó có thể phân tích toàn bộ cơ sở mã, xác định các mẫu nguy hiểm, và cảnh báo lập trình viên về các rủi ro tiềm ẩn. Nghiên cứu này sẽ thúc đẩy việc phát triển các AI 'nhận thức được bảo mật' (security-aware AI), một bước tiến quan trọng cho ngành công nghiệp phần mềm.
Anthropic đề xuất một hệ thống phòng thủ nhiều lớp để đối phó với rủi ro này. Nó bao gồm giám sát chặt chẽ đầu ra của mô hình, phát triển các AI chuyên dụng để phát hiện hành vi tạo mã độc, và tiếp tục nghiên cứu về sự liên kết (alignment) của AI. Họ cũng kêu gọi xây dựng các tiêu chuẩn chung cho toàn ngành để đánh giá những rủi ro này.
Cụ thể, các biện pháp bao gồm: