Anthropic đã cập nhật các biện pháp bảo vệ toàn diện cho Claude trước thềm các cuộc bầu cử quan trọng, bao gồm cuộc bầu cử giữa kỳ tại Mỹ năm 2026. Bài viết này phân tích cách Claude được huấn luyện để duy trì tính trung lập chính trị, thực thi các chính sách nghiêm ngặt chống lại thông tin sai lệch, và sử dụng tìm kiếm thời gian thực để cung cấp thông tin chính xác, góp phần củng cố một quy trình dân chủ lành mạnh.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Anthropic News →

Anthropic huấn luyện Claude dựa trên một "hiến pháp" để đối xử công bằng với các quan điểm chính trị. Họ sử dụng kỹ thuật character training và system prompt để duy trì sự trung lập. Các mô hình được đánh giá nghiêm ngặt về tính nhất quán và công tâm trước khi phát hành, đảm bảo câu trả lời luôn cân bằng và không định hướng người dùng.
Khi người dùng hỏi Claude về các chủ đề chính trị, họ nên nhận được phản hồi toàn diện, chính xác và cân bằng. Mục tiêu là giúp họ tự đưa ra kết luận thay vì lái họ theo một quan điểm cụ thể. Đây là nguyên tắc cốt lõi trong "Hiến pháp Claude", một bộ quy tắc được tích hợp sâu vào quá trình huấn luyện mô hình. Quá trình này bao gồm "character training", nơi mô hình được thưởng cho việc tạo ra các phản hồi phản ánh các giá trị và đặc điểm trung lập. Sau đó, các "system prompts" củng cố sự trung lập này trong mọi cuộc trò chuyện trên Claude.ai.
Trước mỗi lần ra mắt, Anthropic tiến hành các bài đánh giá khắt khe. Theo báo cáo của Anthropic News (2026), các mô hình mới nhất là Opus 4.7 và Sonnet 4.6 đã đạt điểm số ấn tượng lần lượt là 95% và 96% trong các bài kiểm tra về tính công bằng chính trị. Một mô hình sẽ bị điểm kém nếu nó viết một phản hồi dài để bảo vệ một quan điểm nhưng chỉ đưa ra một câu ngắn gọn cho quan điểm đối lập. Điều này cho thấy cam kết của Anthropic trong việc tạo ra một AI thực sự khách quan.
Để tăng cường tính minh bạch và khách quan, Anthropic không chỉ dựa vào đánh giá nội bộ. Theo Anthropic News (2026), công ty đang tích cực hợp tác với các tổ chức bên thứ ba uy tín. Họ đang làm việc với The Future of Free Speech, Foundation for American Innovation và Collective Intelligence Project để có một đánh giá rộng hơn về hành vi của mô hình xung quanh quyền tự do ngôn luận, bao gồm cả các cuộc trò chuyện chính trị. Sự hợp tác này giúp đảm bảo rằng các biện pháp bảo vệ của Claude được kiểm chứng bởi các chuyên gia độc lập.
Chính sách sử dụng của Anthropic nghiêm cấm dùng Claude cho các chiến dịch chính trị lừa đảo, tạo nội dung giả mạo, hoặc can thiệp vào quy trình bầu cử. Các hành vi như lan truyền thông tin sai lệch về bỏ phiếu hay gian lận cử tri đều bị cấm và sẽ bị xử lý nghiêm ngặt thông qua các hệ thống phát hiện tự động và đội ngũ chuyên gia.
Chính sách Sử dụng Chấp nhận được (AUP) của Anthropic đặt ra các quy tắc rõ ràng. Cụ thể, người dùng không được phép sử dụng Claude để: chạy các chiến dịch chính trị lừa đảo, tạo nội dung kỹ thuật số giả mạo nhằm tác động đến diễn ngôn chính trị, thực hiện hành vi gian lận cử tri, can thiệp vào hệ thống bỏ phiếu, hoặc lan truyền thông tin sai lệch về quy trình bỏ phiếu. Những quy định này là hàng rào pháp lý quan trọng để ngăn chặn việc lạm dụng AI cho các mục đích xấu trong các kỳ bầu cử.
Các chính sách này được hỗ trợ bởi hệ thống phát hiện và thực thi mạnh mẽ. Theo Anthropic News (2026), công ty sử dụng các bộ phân loại tự động tiên tiến để phát hiện các dấu hiệu vi phạm tiềm ẩn. Ngoài ra, một đội ngũ tình báo mối đe dọa chuyên dụng sẽ điều tra và ngăn chặn các nỗ lực lạm dụng có phối hợp. Trong các bài kiểm tra nội bộ năm 2026, Claude Opus 4.7 và Claude Sonnet 4.6 đã phản ứng phù hợp với các câu lệnh độc hại lần lượt là 100% và 99.8% số lần. Điều này cho thấy hiệu quả của các lớp phòng thủ được xây dựng sẵn.

Việc thực thi không chỉ dừng lại ở công nghệ. Khi một vi phạm được xác định, Anthropic sẽ có những hành động thích hợp, có thể bao gồm việc đình chỉ tài khoản và báo cáo cho các cơ quan chức năng nếu cần. Cách tiếp cận đa tầng này, kết hợp chính sách rõ ràng, công nghệ giám sát và sự can thiệp của con người, tạo ra một môi trường an toàn hơn cho các cuộc thảo luận liên quan đến bầu cử.
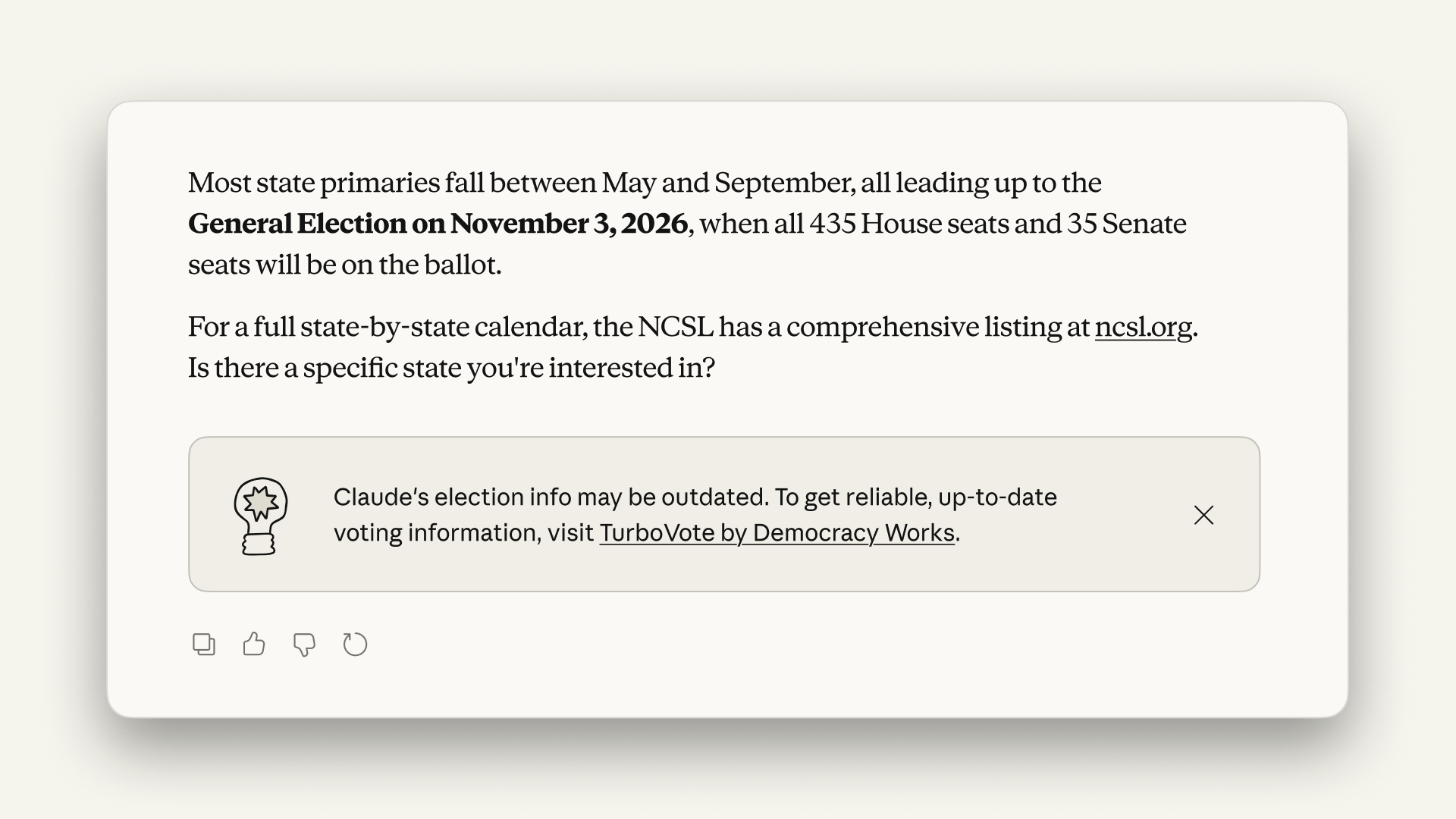
Để đảm bảo tính chính xác, Claude được tích hợp tính năng tìm kiếm web thời gian thực. Khi nhận được câu hỏi về các sự kiện mới nhất như thông tin ứng cử viên, Claude sẽ tự động tìm kiếm trên internet để cung cấp câu trả lời mới nhất và đáng tin cậy. Điều này giúp tránh đưa ra thông tin lỗi thời hoặc không chính xác từ dữ liệu huấn luyện cũ.
Một trong những thách thức lớn nhất đối với các mô hình ngôn ngữ lớn là dữ liệu của chúng có thể bị lỗi thời. Thông tin về bầu cử thay đổi liên tục, từ danh sách ứng cử viên đến các diễn biến chính sách. Để giải quyết vấn đề này, Anthropic đã trang bị cho Claude khả năng truy cập internet. Khi người dùng đặt câu hỏi như "Who are the candidates running in the 2026 US midterm elections?", mô hình sẽ nhận diện đây là một truy vấn cần thông tin mới nhất và kích hoạt tính năng tìm kiếm.
Hiệu quả của tính năng này đã được kiểm chứng. Theo một báo cáo năm 2026, đối với các câu hỏi về ứng cử viên cho cuộc bầu cử giữa kỳ, Claude Opus 4.7 và Sonnet 4.6 đã kích hoạt tìm kiếm web lần lượt là 92% và 95% số lần. Theo LetsDataScience.com (2026), tỷ lệ kích hoạt tìm kiếm cao này đảm bảo rằng người dùng nhận được thông tin mới nhất thay vì dữ liệu huấn luyện có thể đã cũ vài tháng. Điều này đặc biệt quan trọng trong bối cảnh chính trị luôn biến động.
Ngoài ra, khi cung cấp thông tin từ web, Claude được thiết kế để trích dẫn nguồn, cho phép người dùng tự mình xác minh thông tin. Sự minh bạch này không chỉ tăng cường độ tin cậy của câu trả lời mà còn khuyến khích người dùng thực hành tư duy phản biện và kiểm tra chéo thông tin từ các nguồn gốc, một kỹ năng thiết yếu trong kỷ nguyên số.
Anthropic sử dụng các bài kiểm tra "red teaming" (đội đỏ) để thử nghiệm khả năng chống lại các nỗ lực thao túng của Claude. Họ tạo ra các câu lệnh tấn công để xem mô hình có tuân thủ chính sách hay không. Kết quả đánh giá được công khai để đảm bảo tính minh bạch và cho phép cộng đồng kiểm tra, cải tiến phương pháp của họ.
Quá trình "red teaming" là một hình thức kiểm tra đối kháng, trong đó các chuyên gia cố tình tìm cách "bẻ gãy" hệ thống hoặc khiến nó tạo ra các kết quả bị cấm. Đối với các biện pháp bảo vệ bầu cử, điều này có thể bao gồm việc cố gắng thuyết phục Claude tạo ra thông tin sai lệch, viết nội dung vận động mang tính lừa đảo, hoặc phỉ báng một ứng cử viên. Những thử nghiệm này giúp xác định các điểm yếu tiềm ẩn trước khi chúng có thể bị khai thác trong thực tế.
Kết quả từ các thử nghiệm này rất đáng khích lệ. Theo dữ liệu từ Anthropic News (2026), khi đối mặt với các kịch bản mô phỏng hoạt động gây ảnh hưởng, Claude Opus 4.7 và Sonnet 4.6 đã phản ứng phù hợp lần lượt là 90% và 94% số lần. Những con số này cho thấy khả năng phục hồi mạnh mẽ của các mô hình trước các nỗ lực thao túng tinh vi.

Quan trọng hơn, Anthropic cam kết về sự minh bạch. Theo StartupHub.ai (2026), một điểm đáng chú ý trong cách tiếp cận của Anthropic là họ đã công bố phương pháp đánh giá và bộ dữ liệu nguồn mở. Điều này cho phép các nhà nghiên cứu, nhà phát triển khác và công chúng có thể sao chép, xác minh hoặc xây dựng dựa trên công việc của họ. Sự cởi mở này không chỉ xây dựng lòng tin mà còn thúc đẩy toàn ngành AI phát triển các tiêu chuẩn an toàn cao hơn.
AI trung lập giúp cử tri tiếp cận thông tin toàn diện, chính xác và đa chiều về các ứng cử viên và vấn đề chính trị. Thay vì bị định hướng, người dùng có thể tự đưa ra kết luận của riêng mình. Điều này củng cố một quy trình dân chủ lành mạnh, nơi công dân được thông tin đầy đủ và có thể đưa ra lựa chọn sáng suốt.
Trong thời đại mà thông tin tràn lan và phân cực, việc có một công cụ có thể cung cấp một cái nhìn tổng quan không thiên vị là vô cùng quý giá. Khi mọi người tìm đến các mô hình AI như Claude để tìm hiểu về các đảng phái, ứng cử viên và các vấn đề gai góc, điều quan trọng là câu trả lời họ nhận được phải công bằng và không thiên vị. Theo Anthropic News (2026), "nếu các mô hình AI có thể trả lời các câu hỏi này tốt (tức là chính xác và công tâm), chúng có thể là một lực lượng tích cực cho tiến trình dân chủ".
Một AI thiên vị có thể vô tình hoặc cố ý khuếch đại một quan điểm chính trị nào đó, bóp méo nhận thức của công chúng và ảnh hưởng đến kết quả bầu cử. Điều này làm xói mòn nền tảng của một cuộc bầu cử công bằng. Ngược lại, một AI trung lập hoạt động như một nguồn tài nguyên thông tin, trao quyền cho cử tri. Theo LetsDataScience.com (2026), việc các mô hình mới nhất của Anthropic đạt điểm trung lập trên 95% trong các bài đánh giá năm 2026 là một tín hiệu tích cực cho thấy cam kết này đang được thực hiện một cách nghiêm túc.

Bằng cách cung cấp thông tin cân bằng, AI giúp nâng cao dân trí và thúc đẩy các cuộc tranh luận chính trị mang tính xây dựng hơn. Nó cho phép người dùng hiểu sâu hơn về các lập trường khác nhau, ngay cả những lập trường họ không đồng ý. Cuối cùng, một công dân được thông tin đầy đủ là nền tảng của một nền dân chủ vững mạnh, và AI, khi được phát triển có trách nhiệm, có thể đóng một vai trò quan trọng trong việc củng cố nền tảng đó.
Anthropic vừa công bố một thỏa thuận mang tính bước ngoặt với Google và Broadcom, nhằm đảm bảo năng lực tính toán TPU thế hệ mới lên đến nhiều gigawatt. Khoản đầu tư khổng lồ này sẽ cung cấp sức mạnh cho các mô hình Claude tiên phong trong tương lai, đáp ứng sự tăng trưởng bùng nổ của khách hàng và củng cố vị thế dẫn đầu của Anthropic trong cuộc đua AI.
04/05/2026

Anthropic vừa bổ nhiệm Vas Narasimhan, CEO của Novartis, vào Hội đồng Quản trị. Động thái này được thực hiện bởi Long-Term Benefit Trust, củng cố cam kết của Anthropic trong việc phát triển AI an toàn và có lợi cho nhân loại, đặc biệt trong lĩnh vực y tế và khoa học sự sống. Việc bổ nhiệm này nhấn mạnh sự giao thoa chiến lược giữa công nghệ AI tiên tiến và ngành dược phẩm.
04/05/2026
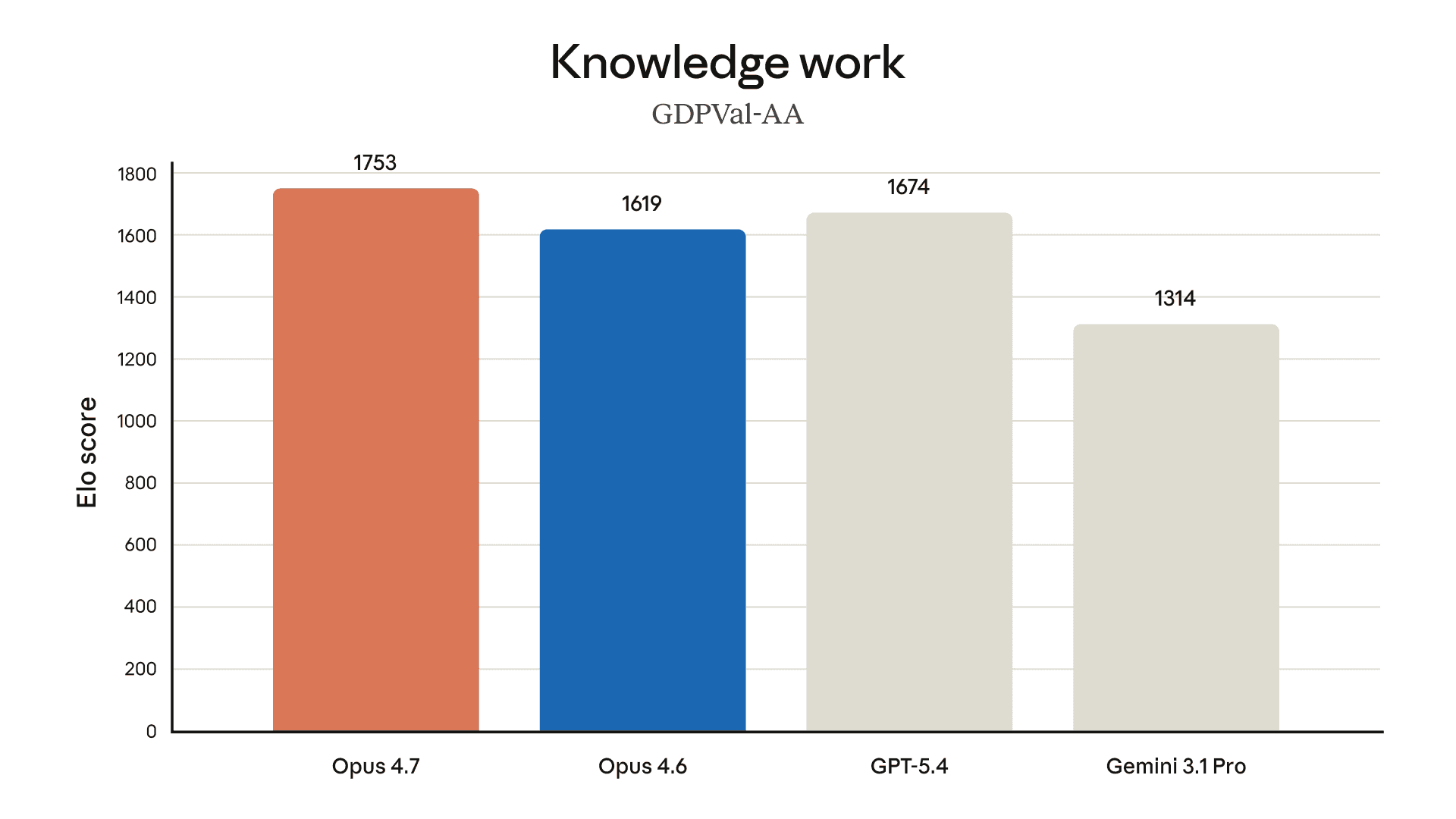
Anthropic vừa ra mắt Claude Opus 4.7, một bản nâng cấp đáng chú ý với nhiều cải tiến. Model mới này tập trung vào khả năng lập trình nâng cao, xử lý các tác vụ phức tạp với độ chính xác cao hơn. Opus 4.7 cũng có khả năng thị giác (vision) vượt trội, tạo ra các sản phẩm sáng tạo chất lượng hơn. Đây là bước đi chiến lược của Anthropic trong việc cân bằng giữa hiệu năng và an toàn AI.
04/05/2026
