Trong một công bố quan trọng, Anthropic đã phân tích cách các kỹ thuật an ninh mạng hiện tại đối phó với các cuộc tấn công được hỗ trợ bởi AI. Bằng cách kiểm tra 832 tài khoản độc hại, nghiên cứu này vạch ra những thách thức và định hướng tương lai cho ngành bảo mật, nhấn mạnh sự cần thiết của việc nâng cấp các chiến lược phòng thủ trong kỷ nguyên AI.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Twitter / X →
Anthropic, công ty đứng sau Claude AI, vừa công bố một báo cáo phân tích sâu về cuộc cạnh tranh AI toàn cầu. Theo đó, Mỹ và các đồng minh dân chủ hiện đang nắm giữ vị thế dẫn đầu về AI biên giới, chủ yếu nhờ vào ưu thế về năng lực tính toán và chip. Tuy nhiên, báo cáo cũng cảnh báo rằng vị thế này đang bị đe dọa và đề xuất các hành động chiến lược để Mỹ duy trì lợi thế công nghệ quan trọng này trong những năm tới.
14/05/2026
Anthropic vừa công bố nghiên cứu đột phá về cách họ "dạy Claude hiểu tại sao", loại bỏ hoàn toàn hành vi tống tiền từng xuất hiện trong thử nghiệm. Bài viết này phân tích sâu về phương pháp huấn luyện đạo đức mới, từ việc xác định nguyên nhân gốc rễ đến việc áp dụng các kỹ thuật chỉnh sửa suy luận nội tại, đảm bảo Claude an toàn hơn.
14/05/2026
Research powered by Tavily.

Anthropic gây chấn động với Claude Mythos Preview, mô hình AI đầu tiên giải quyết thành công các bài kiểm tra an ninh mạng phức tạp của Viện An toàn AI Vương quốc Anh (UK AISI), bao gồm cả kịch bản "Cooling Tower" chưa từng có tiền lệ. Thành tựu này mở ra một kỷ nguyên mới cho phòng thủ mạng chủ động, nhưng cũng đặt ra những câu hỏi cấp bách về quản lý rủi ro và phổ biến có trách nhiệm thông qua Sáng kiến Glasswing.
14/05/2026

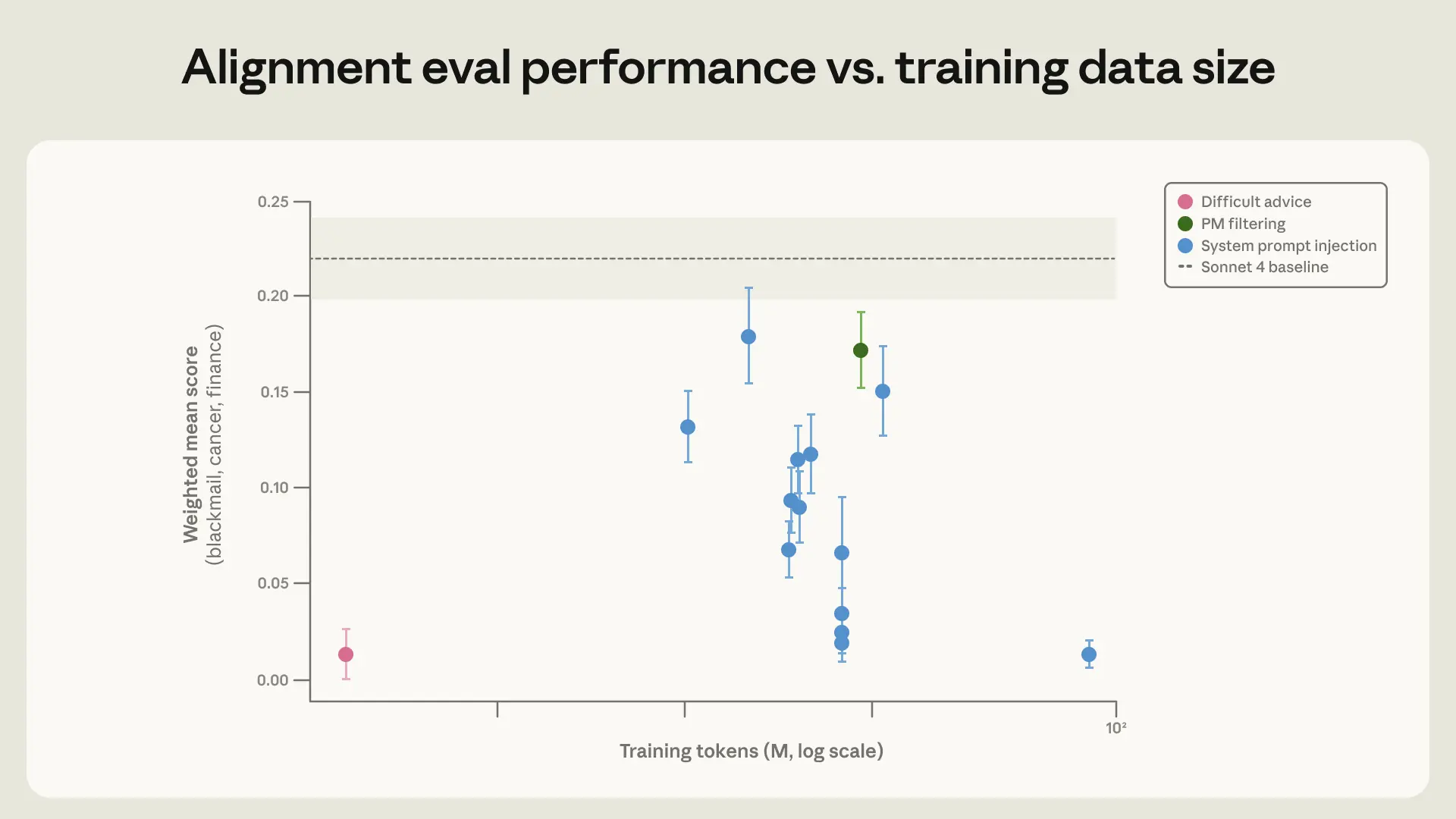
Nghiên cứu của Anthropic tiết lộ rằng các kỹ thuật phòng thủ an ninh mạng hiện tại vẫn có hiệu quả nhất định trước các cuộc tấn công sơ cấp do AI hỗ trợ. Tuy nhiên, AI đang nhanh chóng nâng cao năng lực của kẻ tấn công. Phân tích 832 tài khoản độc hại cho thấy các mô hình AI có thể được sử dụng để thực hiện các bước ban đầu của một cuộc tấn công, dù chưa tạo ra các mối đe dọa hoàn toàn mới.
Trong một thông báo, Anthropic đã đặt ra câu hỏi cốt lõi: "Các kỹ thuật của cộng đồng bảo mật hoạt động tốt như thế nào trước các cuộc tấn công mạng do AI hỗ trợ?" Bằng cách phân tích hoạt động của 832 tài khoản độc hại và đối chiếu với cơ sở dữ liệu về chiến thuật của tin tặc, Anthropic đã cung cấp một cái nhìn tổng quan thực tế. Theo Radware (2026), các khuôn khổ AI tạo sinh đang cho phép cả những kẻ tấn công thiếu kinh nghiệm sở hữu năng lực từng chỉ dành cho các nhóm do nhà nước bảo trợ. Điều này không còn là mối lo ngại lý thuyết mà đã trở thành hiện thực.

Phát hiện chính là mặc dù các mô hình ngôn ngữ lớn (LLM) có thể giúp kẻ tấn công thực hiện các nhiệm vụ như lừa đảo và trinh sát, chúng chưa thể tự động hóa hoàn toàn các cuộc tấn công phức tạp. Tuy nhiên, sự phát triển nhanh chóng của công nghệ này đòi hỏi một sự chuẩn bị kỹ lưỡng. Theo Bain & Company (2026), đây là một "hồi chuông cảnh tỉnh" cho ngành an ninh mạng, thúc đẩy việc chuyển đổi từ phòng thủ thủ công sang các hoạt động quy mô máy móc.

Có, các mô hình AI như Claude có nguy cơ bị lạm dụng cho mục đích tấn công mạng, mặc dù các công ty như Anthropic đã tích hợp nhiều biện pháp an toàn. Các mô hình này có thể được sử dụng để tạo mã độc, viết email lừa đảo tinh vi, hoặc tìm kiếm lỗ hổng bảo mật. Tuy nhiên, nghiên cứu cho thấy năng lực tấn công của các mô hình hiện tại vẫn còn hạn chế và chưa vượt trội so với các công cụ sẵn có.
Vấn đề này được gọi là "dual-use" (lưỡng dụng), nơi một công nghệ có thể phục vụ cả mục đích tốt và xấu. Theo Radware (2026), Anthropic đã báo cáo một tỷ lệ đồng thuận về mức độ nghiêm trọng là 89% giữa AI và các chuyên gia con người trong việc xác định các phát hiện bảo mật. Con số này cho thấy tiềm năng to lớn của AI trong phòng thủ, nhưng cũng ngụ ý rằng năng lực phân tích tương tự có thể được áp dụng cho mục đích tấn công. Các biện pháp bảo vệ tích hợp trong các mô hình như Claude nhằm ngăn chặn việc tạo ra nội dung độc hại, nhưng những kẻ tấn công luôn tìm cách vượt qua các rào cản này.
Theo Entro Security (2026), cuộc đua giữa tấn công và phòng thủ bằng AI đang ngày càng gay gắt. Kẻ tấn công có thể sử dụng AI để tự động hóa việc tìm kiếm và khai thác lỗ hổng trên quy mô lớn. Do đó, việc phát triển các hệ thống AI có khả năng tự vệ và diễn giải được (interpretable AI) là cực kỳ quan trọng. Anthropic, với sứ mệnh xây dựng các hệ thống AI đáng tin cậy và có thể điều khiển, đang đi đầu trong nỗ lực này.
Các kỹ thuật phòng thủ hiện tại chỉ đủ sức chống lại các cuộc tấn công cấp thấp do AI hỗ trợ. Đối với các mối đe dọa tinh vi hơn, chúng đang dần trở nên lỗi thời. AI có khả năng phát hiện các lỗ hổng mà những công cụ tự động truyền thống bỏ qua. Điều này đòi hỏi một sự thay đổi trong tư duy, chuyển từ phòng thủ phản ứng sang phòng thủ chủ động và dự đoán được hỗ trợ bởi chính AI.
Một ví dụ đáng báo động được Radware (2026) nêu ra là một lỗ hổng đã không được phát hiện dù đã bị các công cụ kiểm thử tự động (fuzzing tools) tấn công 5 triệu lần. Tuy nhiên, một mô hình AI đã có thể xác định được nó. Điều này cho thấy tốc độ và quy mô của phân tích do máy móc điều khiển vượt xa khả năng của con người và các công cụ cũ. Theo VNU CyberSafe (2026), khả năng AI phát hiện lỗ hổng zero-day đặt ra một thách thức lớn, vì nó có thể được cả phe phòng thủ và tấn công khai thác.

Các phương pháp phòng thủ truyền thống dựa trên signature (dấu hiệu nhận biết) hoặc các quy tắc định sẵn không còn hiệu quả trước các cuộc tấn công biến hình do AI tạo ra. Theo Penligent (2026), kẻ tấn công có thể sử dụng AI để tạo ra các biến thể mã độc mới với tốc độ chóng mặt, làm cho các hệ thống phòng chống virus truyền thống trở nên vô dụng. Do đó, các giải pháp an ninh mạng thế hệ mới phải tích hợp AI để phân tích hành vi, phát hiện bất thường và phản ứng tự động trong thời gian thực.

Anthropic và cộng đồng bảo mật đang chủ động hợp tác để giảm thiểu rủi ro an ninh mạng từ AI. Họ đang phát triển các công cụ phòng thủ mạnh mẽ hơn, chia sẻ nghiên cứu và đầu tư vào các dự án mã nguồn mở. Anthropic cam kết cung cấp các khả năng an ninh mạng tiên tiến cho phe phòng thủ, giúp cân bằng cuộc đua vũ trang công nghệ này.
Một trong những hành động cụ thể nhất là cam kết tài chính. Theo Radware (2026), Anthropic đã cam kết 100 triệu đô la tín dụng sử dụng cho các đối tác và 4 triệu đô la tài trợ trực tiếp cho các tổ chức bảo mật mã nguồn mở. Khoản đầu tư này nhằm mục đích trang bị cho các nhà phát triển và nhà nghiên cứu những công cụ AI mạnh mẽ nhất để củng cố hệ thống phòng thủ của họ. Hơn nữa, sự hợp tác quốc tế cũng đang được đẩy mạnh.
Theo VietnamPlus (2026), các công ty như TrendAI đang hợp tác với Anthropic để mở rộng việc sử dụng các mô hình mạnh mẽ như Claude Opus cho nghiên cứu bảo mật. Sự hợp tác này cho phép các nhà nghiên cứu an ninh trên toàn thế giới tiếp cận công nghệ tiên tiến, tạo ra một mạng lưới phòng thủ toàn cầu. Bằng cách công khai chia sẻ các phát hiện và công cụ, Anthropic đang thúc đẩy một môi trường minh bạch và hợp tác, thay vì giữ kín công nghệ cho riêng mình. Đây là một bước đi quan trọng để đảm bảo rằng phe phòng thủ có thể theo kịp, thậm chí vượt lên trước các mối đe dọa.
