Claude Opus đang chứng tỏ là mô hình AI hàng đầu cho các tác vụ phức tạp, kéo dài. Dựa trên chia sẻ từ chuyên gia Boris Cherny của Anthropic, bài viết này cung cấp 5 mẹo thiết thực để bạn khai thác tối đa sức mạnh của Opus, cho phép nó hoạt động tự trị trong nhiều giờ, thậm chí nhiều ngày, từ việc tự động hóa quyền cho đến tự xác minh kết quả.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Twitter / X →
Dự án Pilot của nhóm Frontier Red Team từ Anthropic đang nghiên cứu khả năng AI điều khiển drone. Mục tiêu là khám phá giới hạn và tiềm năng của trí tuệ nhân tạo trong việc vận hành các thiết bị bay không người lái.
25/07/2026
Opus 5 is a step change improvement for the Opus tier powering long-running agents while delivering improvements in coding and professional work.
24/07/2026
Anthropic vừa ra mắt Claude dành cho giáo viên, một công cụ AI mạnh mẽ được thiết kế để hỗ trợ các nhà giáo dục. Claude có thể giúp giáo viên trong nhiều tác vụ, từ chuẩn bị bài giảng đến hỗ trợ học sinh, giúp tiết kiệm thời gian và nâng cao hiệu quả giảng dạy.
15/07/2026
Anthropic cam kết đầu tư 10 triệu USD để thúc đẩy nghiên cứu trí tuệ nhân tạo tại Canada. Khoản tài trợ này nhằm hỗ trợ các dự án AI tiên tiến và phát triển nhân tài trong lĩnh vực này.
15/07/2026
Claude Opus được xem là mô hình tốt nhất cho công việc dài hơi vì khả năng duy trì sự mạch lạc và hiệu suất vượt trội trên các benchmark phức tạp. Nó có thể xử lý các dự án lớn, như viết lại toàn bộ codebase, mà không mất đi ngữ cảnh. Các bài kiểm tra như SWE-Marathon cho thấy khả năng của Opus trong việc thực thi các nhiệm vụ kéo dài hàng giờ hoặc ngày.
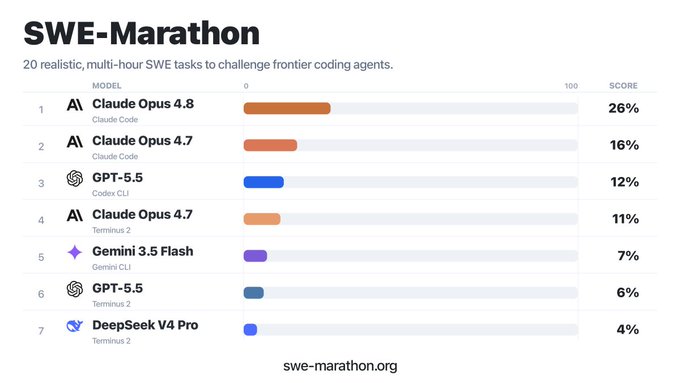
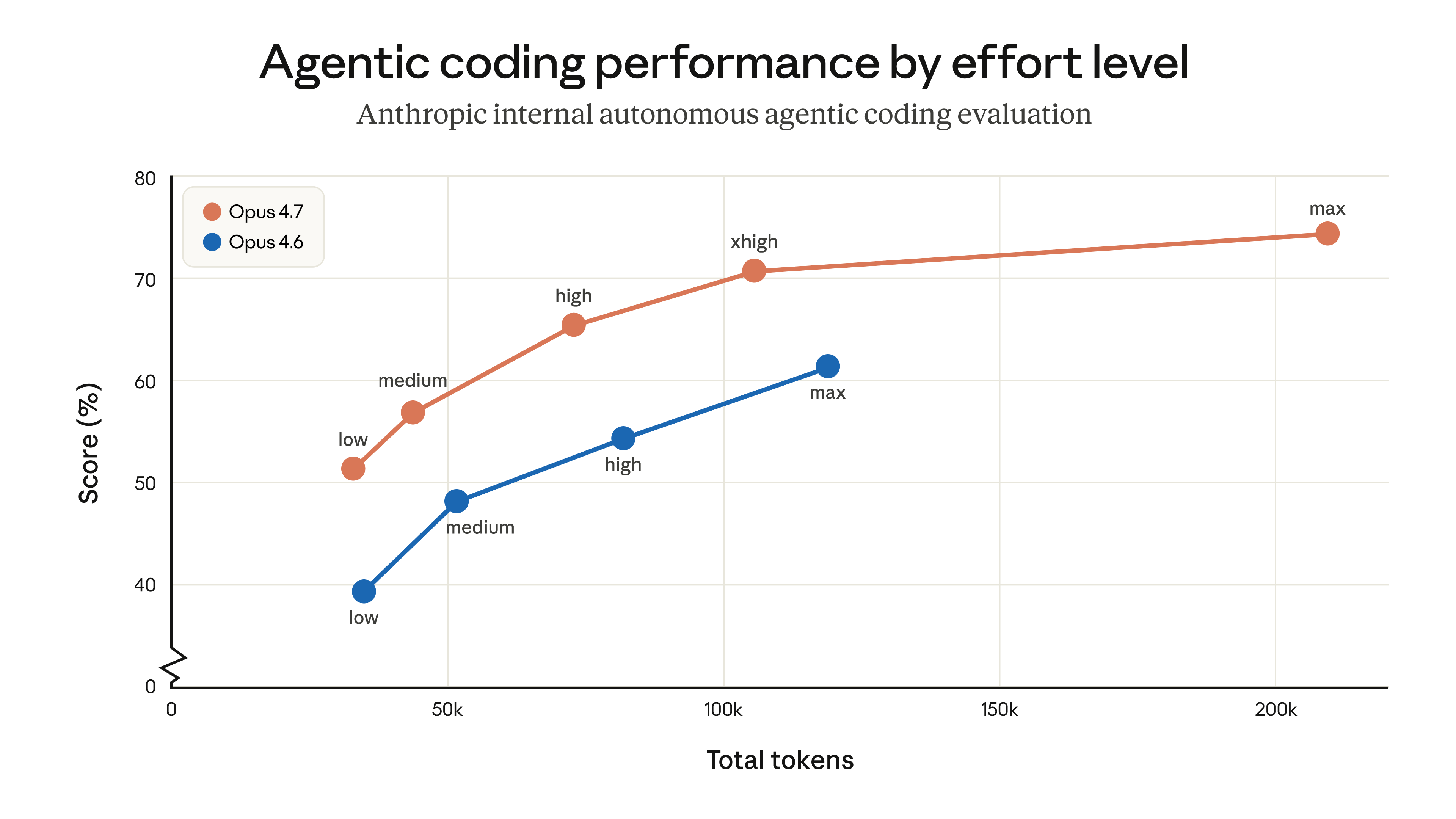
Sự trỗi dậy của các agent AI tự trị đã đặt ra yêu cầu mới cho các mô hình ngôn ngữ lớn (LLM). Chúng không chỉ cần thông minh mà còn phải bền bỉ. Theo Boris Cherny từ Anthropic (2026), các benchmark đang ngày càng cho thấy Opus là lựa chọn tối ưu cho loại công việc này. Ví dụ, benchmark SWE-Marathon thử thách các agent AI với ngân sách lên tới 1 tỷ token để xem chúng có thể duy trì sự mạch lạc hay không. Đây là một bài kiểm tra khắc nghiệt về khả năng lập trình dài hạn.
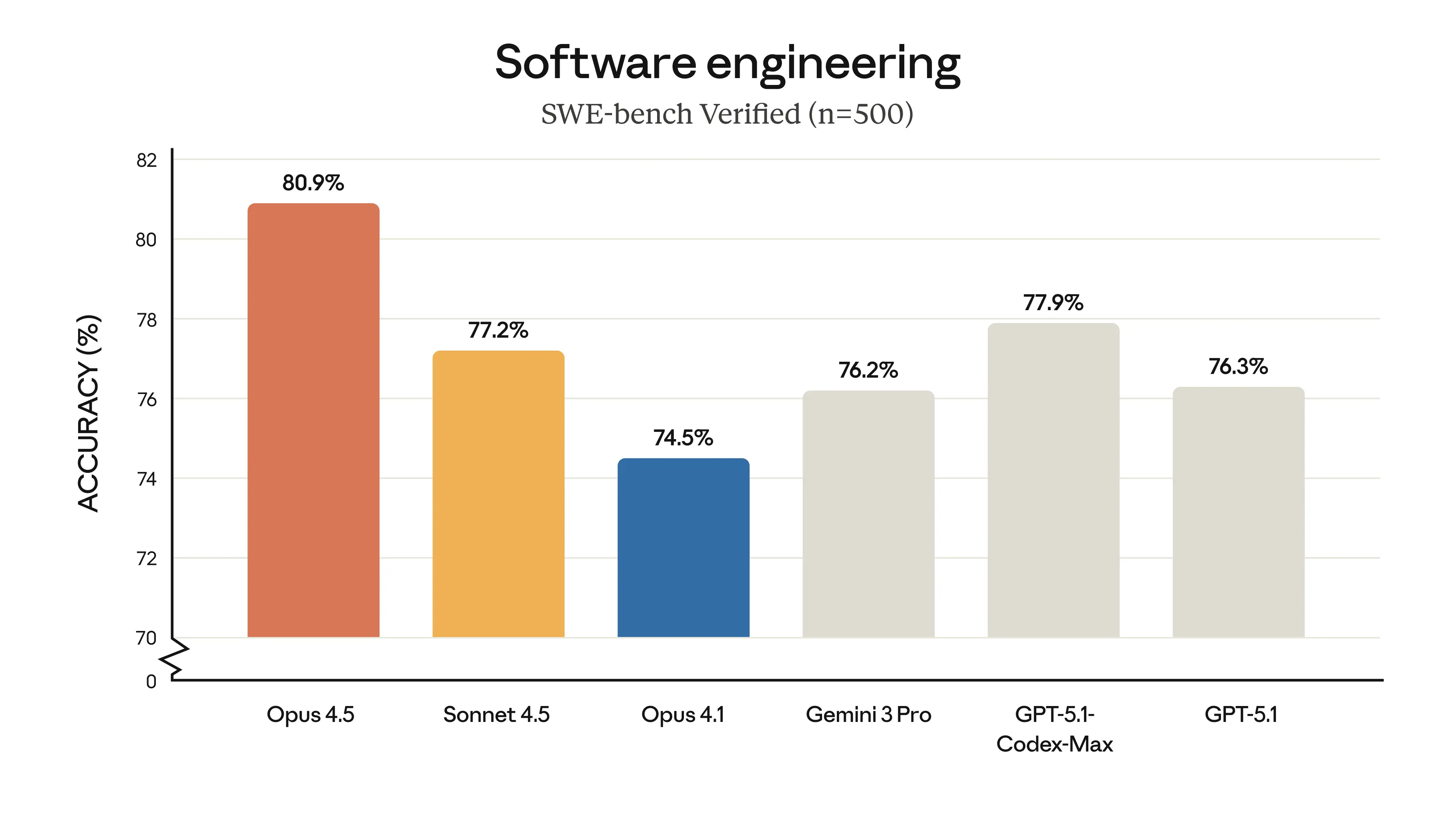
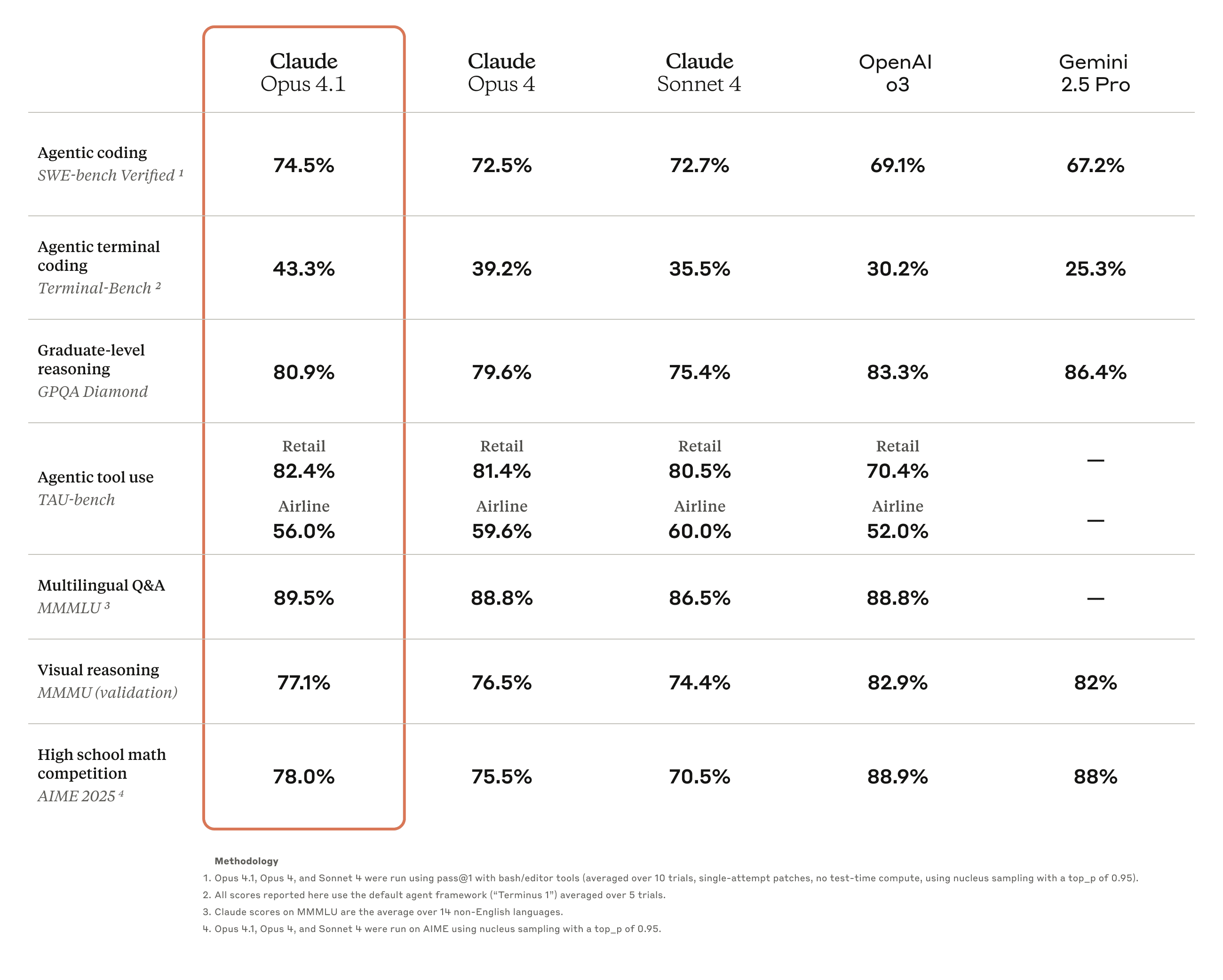
Các số liệu độc lập cũng củng cố vị thế này. Theo MorphLLM (2026), Claude Opus 4.5 đạt điểm số ấn tượng 80.9% trên một tập hợp các bài kiểm tra tổng hợp, vượt qua các đối thủ cạnh tranh. Khả năng xử lý các cửa sổ ngữ cảnh lớn và duy trì logic phức tạp qua nhiều bước giúp Opus trở thành công cụ đáng tin cậy cho các nhà phát triển và nhà nghiên cứu. Điều này mở ra khả năng tự động hóa các nhiệm vụ trước đây đòi hỏi sự can thiệp liên tục của con người.
Để tự động hóa hoàn toàn các tác vụ của Claude, bạn nên sử dụng chế độ "auto mode" cho quyền và "dynamic workflows" cho quy trình. Chế độ tự động cho phép Claude thực hiện các hành động mà không cần chờ phê duyệt thủ công. Quy trình làm việc động cho phép Claude điều phối hàng trăm hoặc hàng ngàn agent phụ để hoàn thành một mục tiêu phức tạp, giúp giảm đáng kể sự giám sát của con người.
Boris Cherny nhấn mạnh tầm quan trọng của việc giảm thiểu sự can thiệp của con người. Trong chia sẻ của mình, ông nói: "Sử dụng auto mode cho quyền, để Claude không cần hỏi xin phê duyệt". Theo x.com (2026), đây là bước đầu tiên để biến Claude từ một trợ lý thành một nhân viên tự trị. Khi chạy các tác vụ kéo dài hàng giờ, mỗi lần dừng lại để chờ xác nhận sẽ phá vỡ luồng công việc và làm giảm hiệu quả.
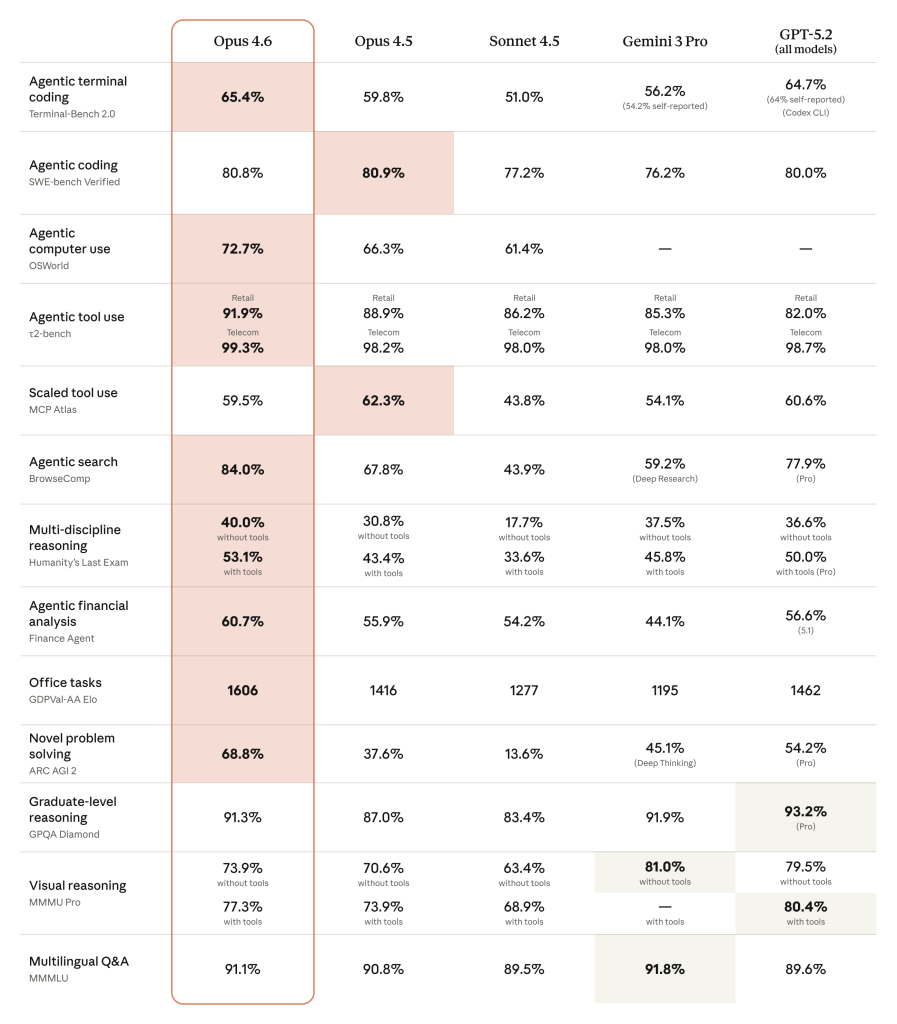
Bên cạnh đó, "dynamic workflows" là một tính năng thay đổi cuộc chơi. Nó cho phép Claude tự phân rã một nhiệm vụ lớn thành các nhiệm vụ con và giao cho các agent chuyên biệt. Theo Digital Applied (2026), các phiên bản mới như Claude Opus 4.8 đã cải tiến mạnh mẽ khả năng này. Thay vì chỉ tuân theo một kịch bản cứng nhắc, Claude có thể linh hoạt tạo và điều chỉnh kế hoạch khi gặp các vấn đề không lường trước. Dữ liệu từ MorphLLM (2026) cho thấy Claude Opus 4.6 cũng duy trì hiệu suất cao với điểm số 80.8%, chứng tỏ sự ổn định qua các phiên bản.

Để đảm bảo Claude không từ bỏ giữa chừng, bạn có thể sử dụng các lệnh đặc biệt như `/goal` hoặc `/loop`. Những lệnh này hoạt động như một cú hích, nhắc nhở Claude tiếp tục làm việc cho đến khi mục tiêu đã xác định được hoàn thành. Chúng rất hữu ích trong các nhiệm vụ lặp đi lặp lại hoặc các mục tiêu phức tạp đòi hỏi sự kiên trì để đạt được kết quả cuối cùng.
Việc duy trì sự tập trung của một agent AI trong thời gian dài là một thách thức kỹ thuật. Các mô hình có thể "quên" mục tiêu ban đầu hoặc đi chệch hướng. Lệnh `/goal` thiết lập một mục tiêu rõ ràng, trong khi `/loop` khuyến khích việc lặp lại một quy trình cho đến khi đạt được điều kiện dừng. Theo Stob.AI (2026), các phiên bản Claude mới hơn cung cấp khả năng "kiểm soát nỗ lực" (effort control) tốt hơn, cho phép người dùng điều chỉnh mức độ "suy nghĩ" của mô hình. Điều này kết hợp với các lệnh như `/loop` tạo ra một công cụ mạnh mẽ.
Hiệu suất của mô hình cũng đóng vai trò quan trọng. Một mô hình mạnh mẽ hơn sẽ ít có khả năng bị "mắc kẹt" hơn. Ví dụ, dữ liệu từ MorphLLM (2026) cho thấy Claude Sonnet 4.6, một mô hình cấp thấp hơn Opus, vẫn đạt được điểm số đáng nể là 79.6%. Điều này cho thấy kiến trúc chung của gia đình Claude được xây dựng để hướng tới sự bền bỉ, và Opus là đỉnh cao của triết lý thiết kế đó.
Bạn có thể chạy các tác vụ Claude dài hạn mà không cần bật máy tính bằng cách sử dụng Claude Code trên nền tảng đám mây. Quá trình xử lý thực sự diễn ra trên máy chủ của Anthropic. Bạn chỉ cần khởi tạo tác vụ thông qua ứng dụng máy tính để bàn hoặc di động, sau đó bạn có thể đóng laptop hoặc tắt điện thoại mà không làm gián đoạn công việc của AI.
Đây là một trong những lợi ích chính của kiến trúc dựa trên đám mây. Theo Boris Cherny (2026), cách dễ nhất là sử dụng ứng dụng desktop hoặc mobile. Chúng hoạt động như một giao diện điều khiển từ xa cho phiên làm việc của Claude trên cloud. Điều này giải phóng tài nguyên máy tính cá nhân của bạn và đảm bảo tác vụ không bị ảnh hưởng bởi các sự cố như mất kết nối internet tạm thời hoặc hết pin laptop.
Theo Caylent (2026), kinh tế học của các agent chạy dài hạn đang thay đổi nhờ các mô hình hiệu quả như Claude. Chi phí để chạy một agent trong 24 giờ đã giảm đáng kể, làm cho việc triển khai các giải pháp tự trị trở nên khả thi hơn về mặt tài chính. Các mô hình như Claude Opus, với hiệu suất hàng đầu được ghi nhận bởi các benchmark như của MorphLLM (2026) nơi nó đạt 80.9%, là trung tâm của sự chuyển dịch này.
Tự xác minh là bước tối quan trọng vì nó đảm bảo chất lượng và tính đúng đắn của công việc do agent AI thực hiện. Đối với các tác vụ dài hạn, một lỗi nhỏ ban đầu có thể lan truyền và gây ra các vấn đề lớn sau này. Bằng cách cung cấp cho Claude một phương pháp để tự kiểm tra công việc của mình từ đầu đến cuối, bạn tạo ra một vòng lặp phản hồi giúp nó tự sửa lỗi và đảm bảo kết quả cuối cùng hoạt động như mong đợi.
Boris Cherny, trong chia sẻ trên x.com (2026), đã đưa ra các ví dụ cụ thể. Đối với công việc liên quan đến web, hãy sử dụng tiện ích mở rộng Claude trong trình duyệt Chrome. Đối với ứng dụng di động, hãy dùng một trình giả lập iOS/Android như MCP (Mobile C-suite P). Đối với công việc backend, hãy cung cấp cho Claude khả năng khởi động toàn bộ máy chủ web hoặc dịch vụ. Những cơ chế này cho phép Claude không chỉ viết mã mà còn chạy và kiểm thử nó trong một môi trường thực tế.
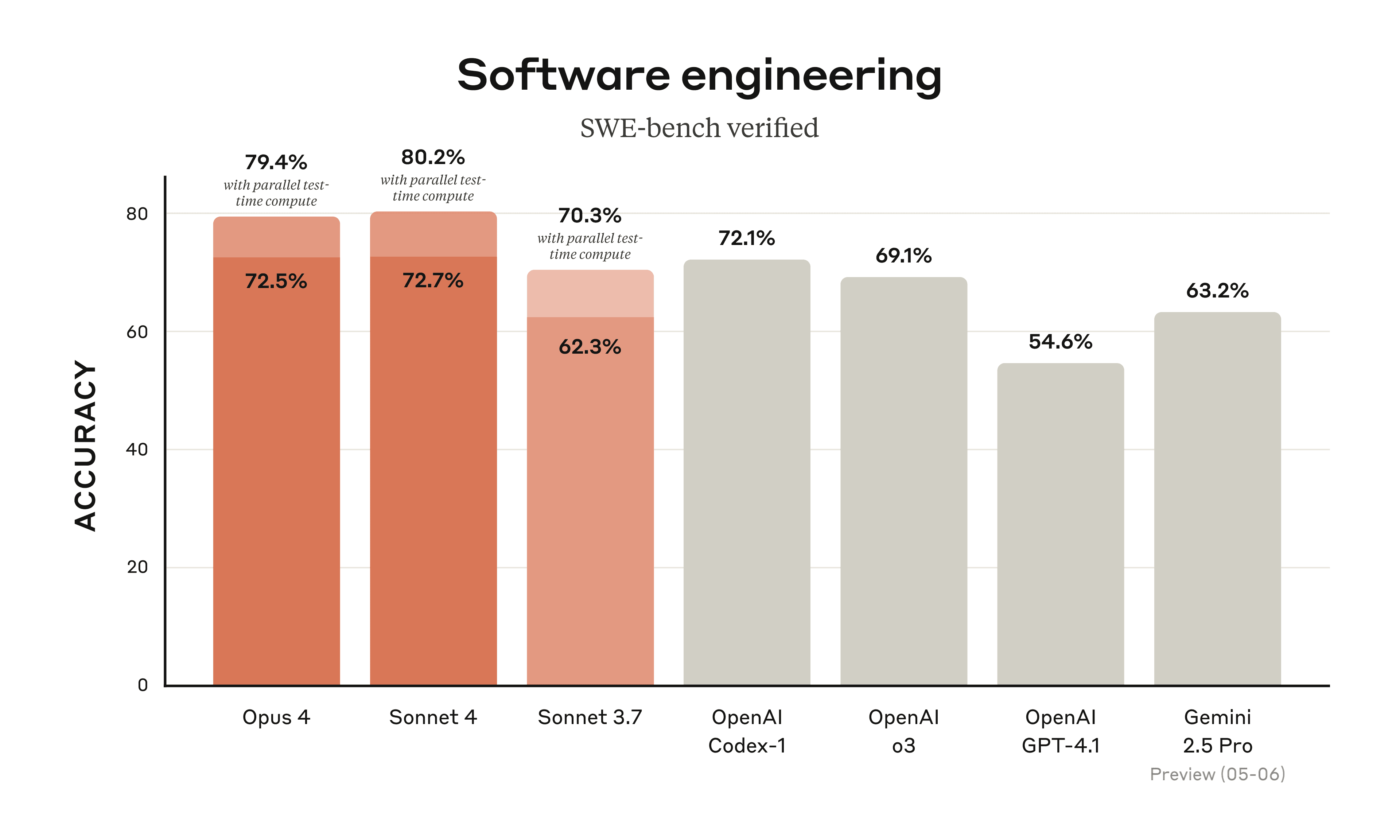
Theo Vellum (2026), các benchmark cho các phiên bản Claude Opus mới hơn ngày càng tập trung vào các nhiệm vụ thực tế, nơi việc xác minh đầu ra là một phần của quy trình. Một mô hình có thể tạo ra mã trông có vẻ đúng nhưng không thể biên dịch hoặc chạy được thì không hữu ích. Khả năng tự xác minh này là một trong những lý do tại sao Claude Opus hoạt động tốt trên các bài kiểm tra như SWE-bench. Dữ liệu từ Tech Insider (2026) cũng cho thấy sự chênh lệch lớn về hiệu suất trên các benchmark thực tế này, nhấn mạnh tầm quan trọng của việc xác minh end-to-end.