Khi các mô hình AI như Claude ngày càng mạnh mẽ, việc kiểm soát 'vùng ảnh hưởng' (blast radius) của chúng trở thành ưu tiên hàng đầu. Bài viết này phân tích sâu các chiến lược kỹ thuật mà Anthropic sử dụng, từ sandbox đến giám sát hành vi, để đảm bảo Claude hoạt động an toàn trên các sản phẩm claude.ai, Claude Code và Cowork, cân bằng giữa hiệu suất và rủi ro.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Anthropic Engineering →
Khi AI mạnh hơn, rủi ro tiềm ẩn cũng lớn hơn. Việc kiểm soát "vùng ảnh hưởng" (blast radius) là cách giới hạn thiệt hại tối đa mà một AI có thể gây ra. Đây là yếu tố then chốt để triển khai các mô hình mạnh mẽ một cách an toàn. Nó giúp cân bằng giữa việc khai thác lợi ích và quản lý rủi ro hiệu quả.
Các tác nhân AI đang ngày càng có năng lực hơn. Chúng có thể thực hiện các công việc từng đòi hỏi một người hoặc cả một nhóm. Điều này tạo ra một phép tính rủi ro-lợi ích mới. Chi phí của việc không triển khai AI trở nên quá lớn. Do đó, việc áp dụng AI là xu hướng tất yếu, miễn là sản phẩm có thể được làm cho an toàn. Theo Anthropic Engineering (2026), câu hỏi kỹ thuật đặt ra là làm thế nào để giới hạn vùng ảnh hưởng này.
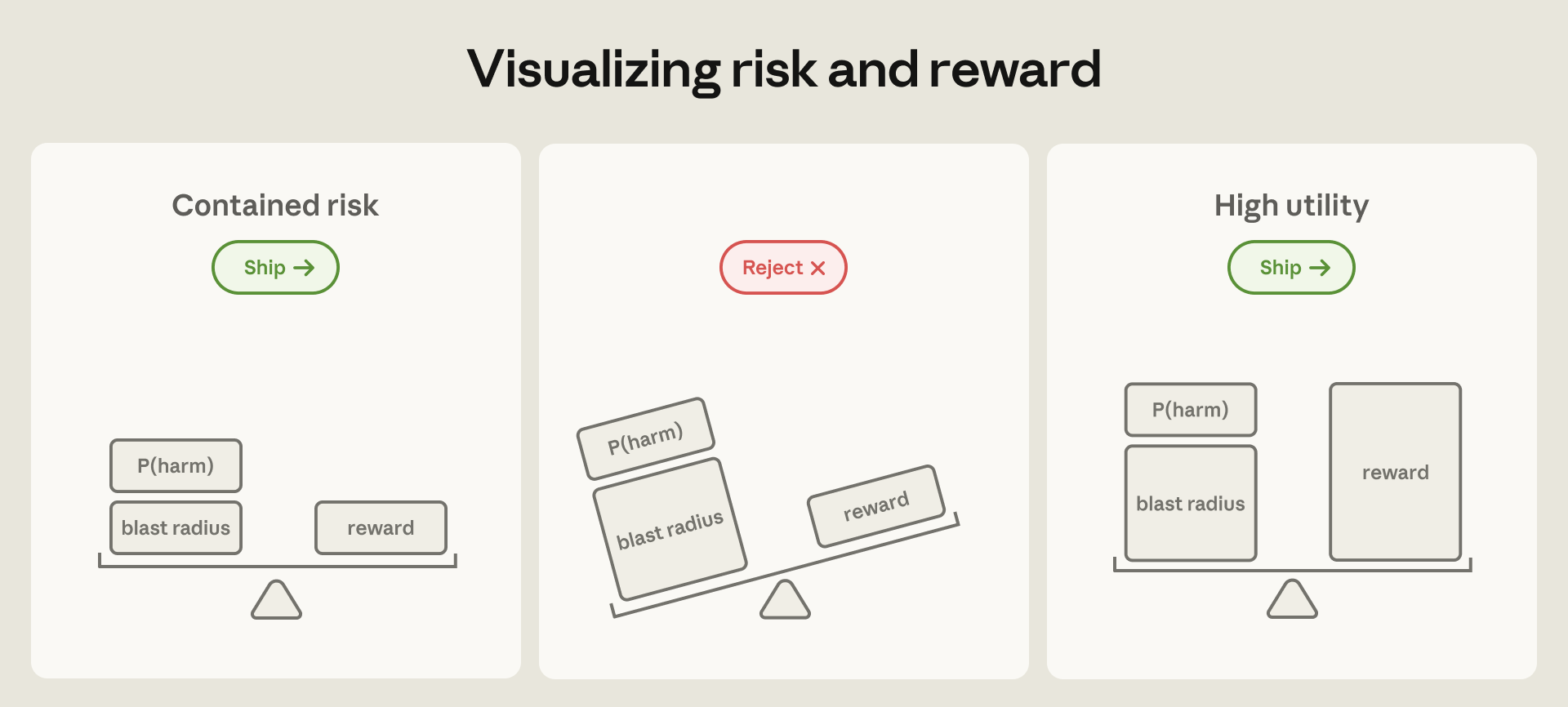
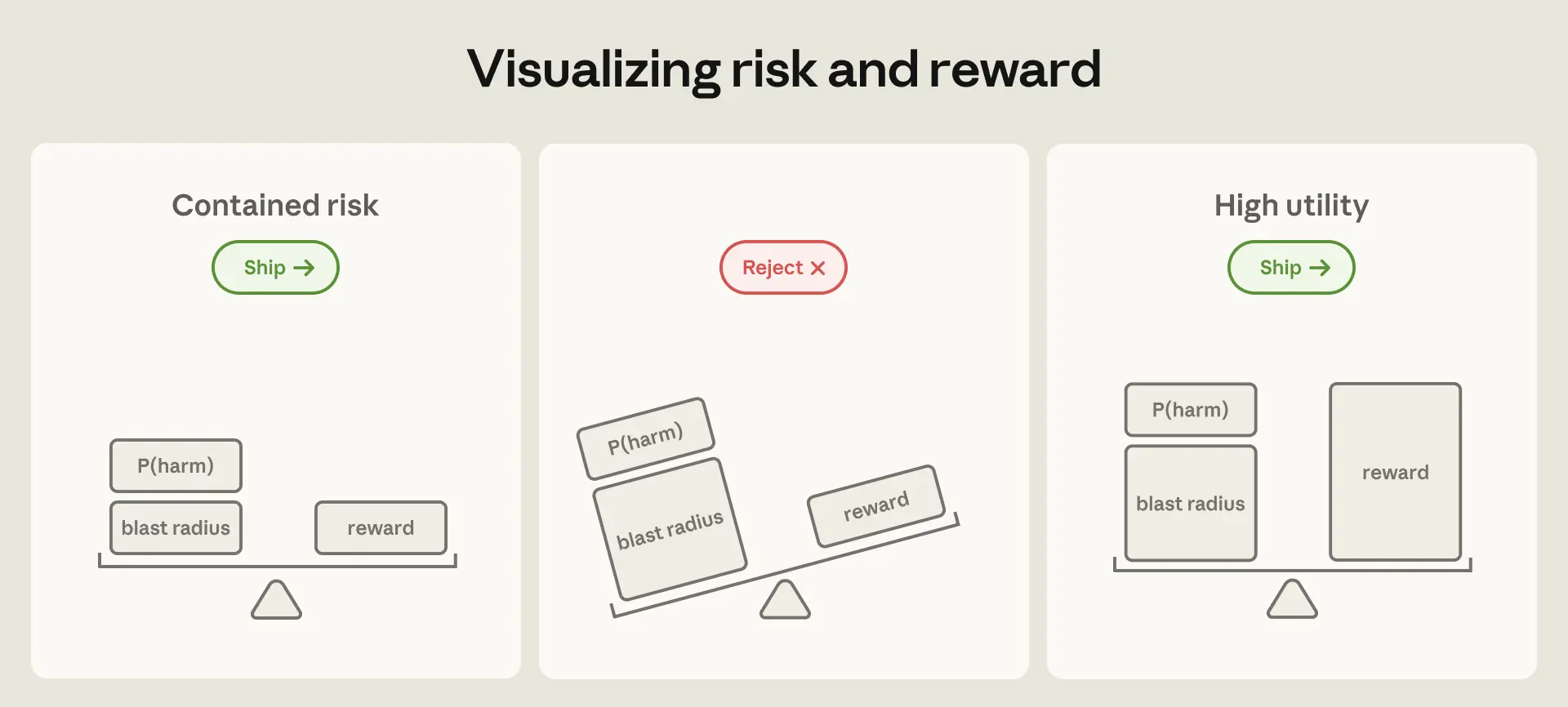
Vùng ảnh hưởng lý thuyết chỉ tăng lên khi khả năng và quyền truy cập của AI mở rộng. Một mô hình có quyền truy cập vào hệ thống nội bộ có thể gây ra thiệt hại lớn hơn một chatbot đơn thuần. Thách thức không phải là loại bỏ hoàn toàn rủi ro, mà là quản lý nó. Chúng ta cần đảm bảo rằng ngay cả khi có sự cố xảy ra, thiệt hại vẫn nằm trong giới hạn chấp nhận được.
Một ví dụ điển hình là sự mệt mỏi khi phê duyệt. Dữ liệu của Anthropic cho thấy người dùng có xu hướng mất cảnh giác theo thời gian. Theo Anthropic Engineering (2026), các phép đo từ xa cho thấy người dùng đã phê duyệt khoảng 93% lời nhắc cấp quyền. Con số này cho thấy việc chỉ dựa vào sự giám sát của con người là không đủ. Cần có các biện pháp kiểm soát kỹ thuật vững chắc hơn.
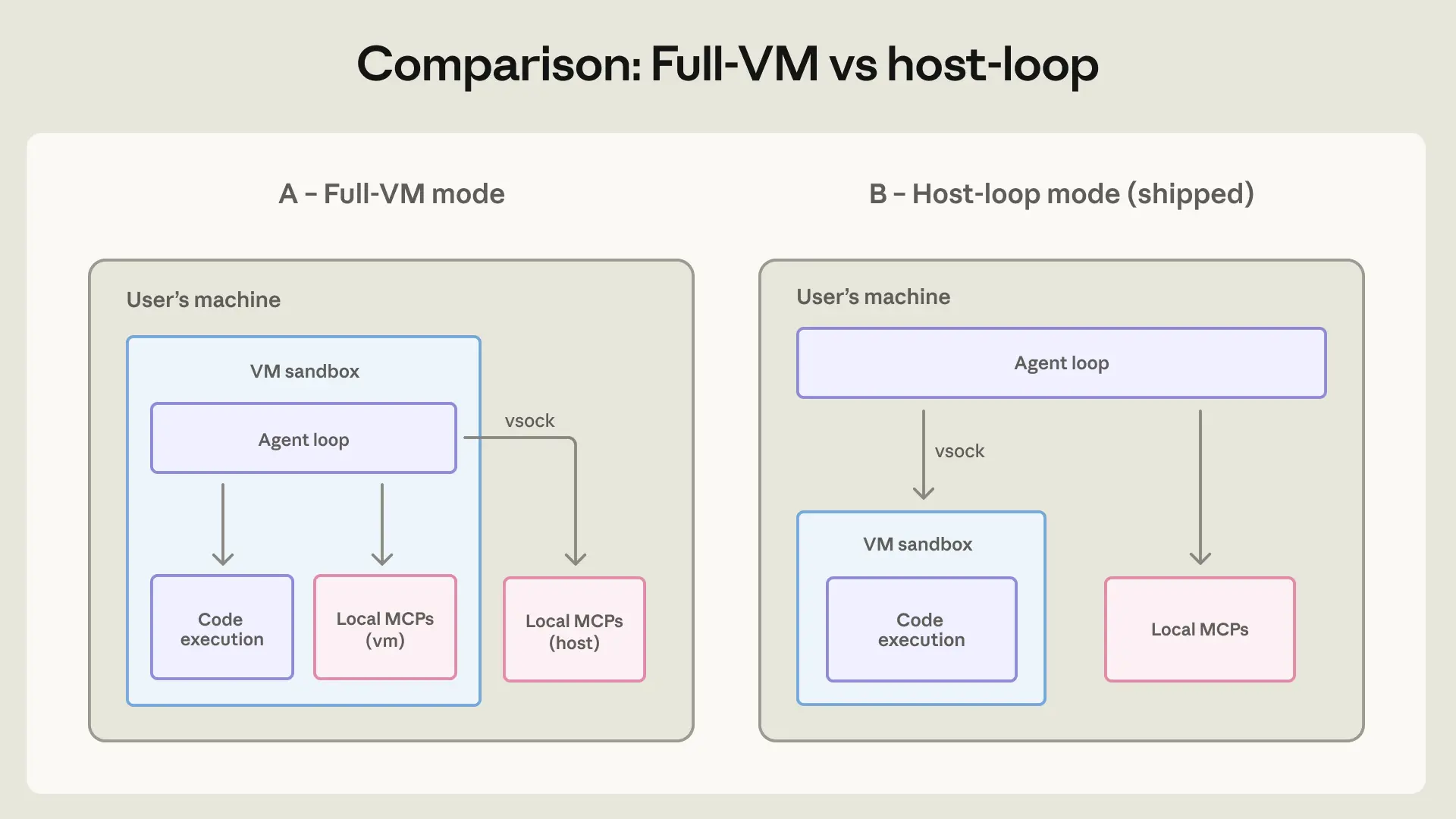
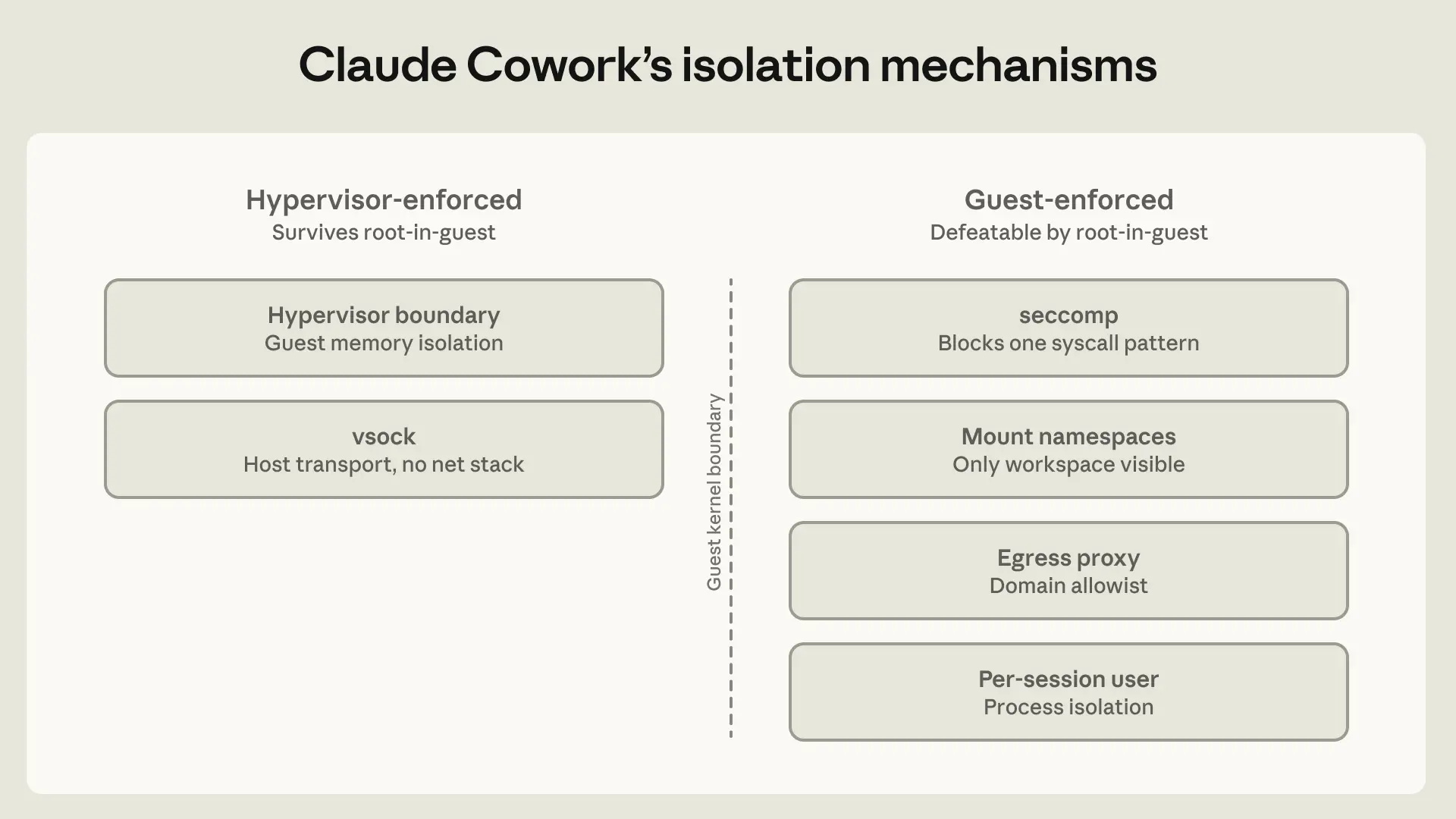
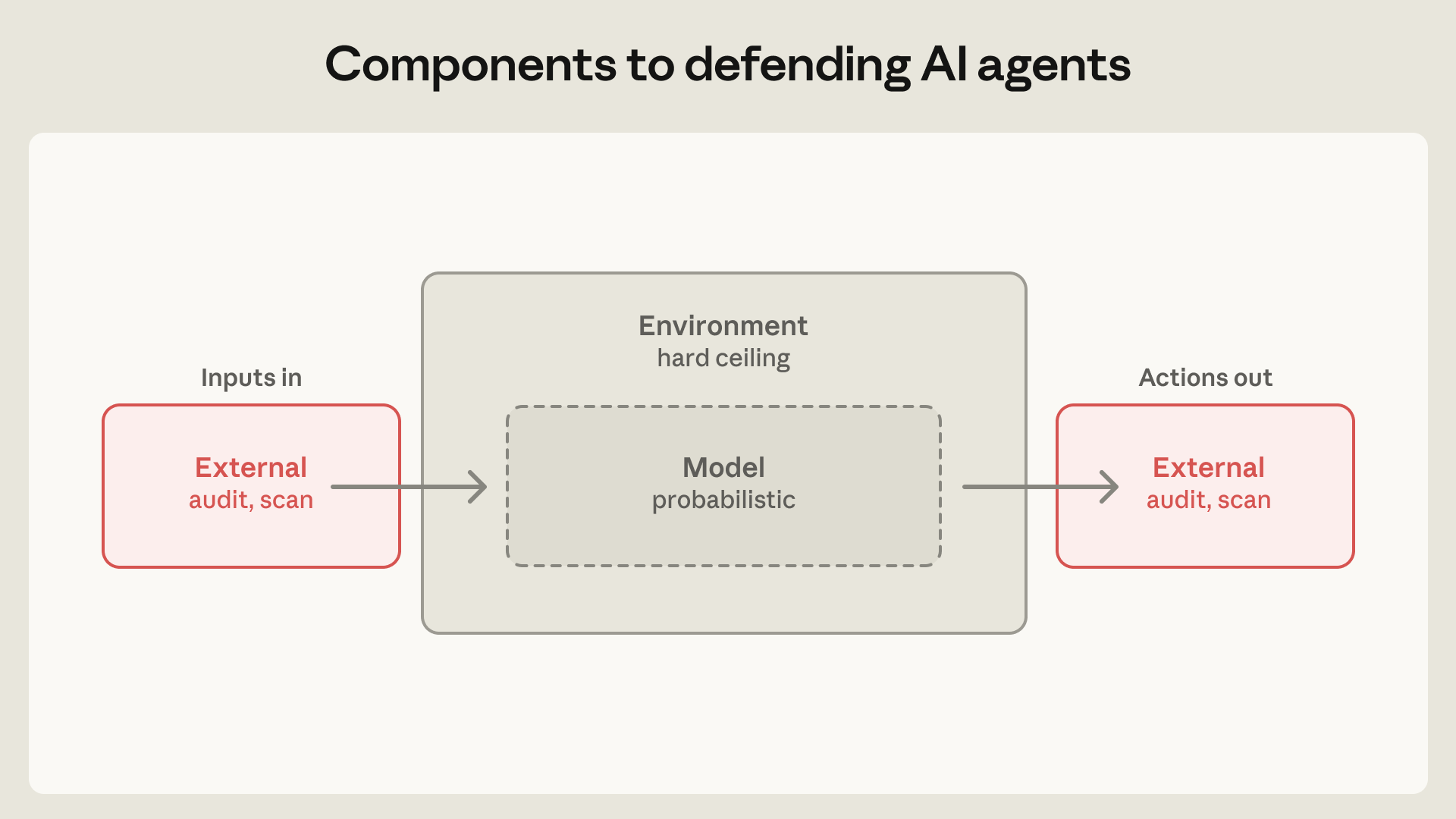
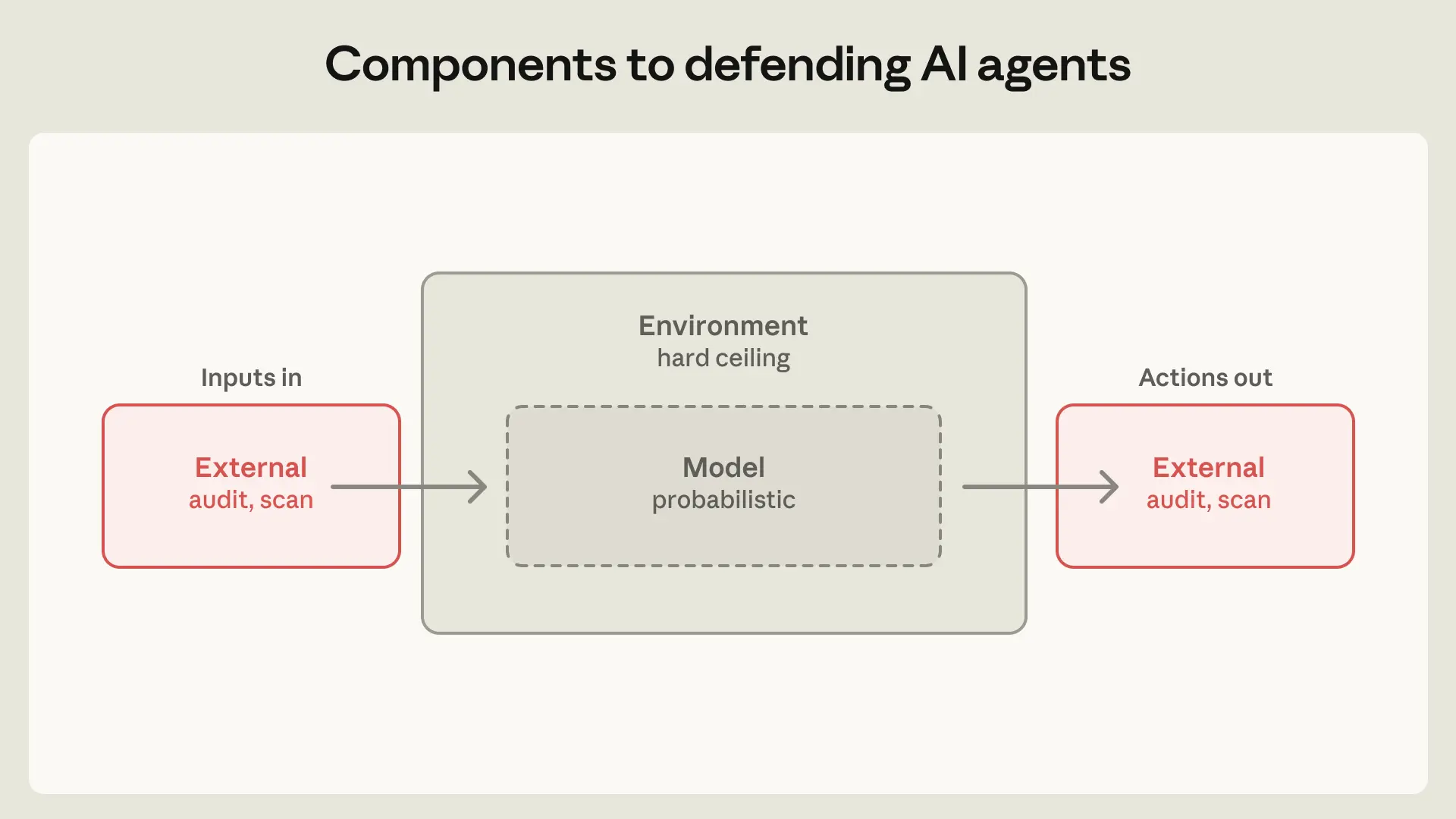
Anthropic sử dụng hai phương pháp chính để kiểm soát Claude. Đầu tiên là giám sát hành vi có sự tham gia của con người. Thứ hai là kiểm soát môi trường hoạt động, hay còn gọi là "containment". Phương pháp thứ hai được chú trọng hơn, sử dụng các công nghệ như sandbox, máy ảo và kiểm soát truy cập để giới hạn khả năng của AI một cách chặt chẽ.
Phương pháp giám sát bởi con người (human-in-the-loop) tỏ ra có thể sai lầm. Như đã đề cập, người dùng có xu hướng phê duyệt hầu hết các yêu cầu, dẫn đến "mệt mỏi phê duyệt". Điều này làm giảm hiệu quả của lớp bảo vệ này. Theo Anthropic Engineering (2026), cách tiếp cận này về mặt lý thuyết là hiệu quả, nhưng thực tế lại có nhiều thiếu sót. Anthropic nhận thấy cần một giải pháp chủ động hơn là chỉ dựa vào sự cảnh giác của người dùng.
Do đó, trọng tâm chính được chuyển sang containment. Thay vì giám sát những gì AI làm, chúng ta giám sát những gì nó có thể làm. Bằng cách thực thi các ranh giới truy cập nghiêm ngặt, Anthropic có thể giới hạn vùng ảnh hưởng của Claude. Các kỹ sư đã dành nhiều nỗ lực nhất cho lĩnh vực này. Đây cũng là nơi xảy ra nhiều sự cố bảo mật bất ngờ nhất, mang lại những bài học quý giá. Một ví dụ thành công là chế độ tự động của Claude Code. Theo Anthropic Engineering (2026), tính năng này đã giúp giảm 84% số lượng lời nhắc cấp quyền, tăng năng suất mà vẫn đảm bảo an toàn.
Mỗi sản phẩm của Claude có một kiến trúc kiểm soát riêng, phù hợp với đối tượng và rủi ro. Claude Code dùng sandbox nghiêm ngặt để thực thi mã. Claude.ai tập trung vào lọc nội dung và hành vi an toàn. Trong khi đó, Claude Cowork quản lý quyền truy cập trong môi trường cộng tác nhiều người dùng, tạo ra một lớp bảo vệ khác.
Với Claude Code, một công cụ dành cho lập trình viên, rủi ro chính là việc thực thi mã không an toàn. Ban đầu, Claude Code yêu cầu người dùng cho phép từng hành động. Nhưng điều này gây ra sự mệt mỏi. Chế độ tự động mới ra đời đã giải quyết vấn đề này. Nó sử dụng một bộ phân loại dựa trên mô hình để tự động phê duyệt các lệnh an toàn. Theo Anthropic Engineering (2026), bộ phân loại này chỉ chặn khoảng 0.4% lệnh lành tính. Tuy nhiên, nó cũng bỏ lỡ khoảng 17% các hành động rủi ro, cho thấy đây là một lớp phòng thủ trong chiến lược sâu rộng hơn, không phải là giải pháp duy nhất.
Đối với claude.ai, sản phẩm chatbot chính, việc kiểm soát tập trung vào ngăn chặn các hành vi lạm dụng và tạo ra nội dung độc hại. Hệ thống được huấn luyện để từ chối các yêu cầu vi phạm chính sách sử dụng. Đây là lớp phòng thủ ở cấp độ mô hình.
Claude Cowork, một công cụ cộng tác, lại có một thách thức khác. Nó cần quản lý quyền truy cập của AI vào các tài liệu và dữ liệu trong một không gian làm việc chung. Việc kiểm soát ở đây liên quan đến việc xác định AI có thể đọc và ghi vào đâu, dựa trên quyền của người dùng đã triệu tập nó. Theo Anthropic Engineering (2026), việc xây dựng các hệ thống kiểm soát riêng biệt cho từng sản phẩm đã mang lại nhiều bài học quý báu.
Có ba loại rủi ro bảo mật chính đối với các tác nhân AI. Thứ nhất là người dùng lạm dụng, dù cố ý hay vô ý. Thứ hai là mô hình hoạt động sai, tạo ra kết quả không mong muốn. Thứ ba là tấn công từ bên ngoài, khai thác lỗ hổng để chiếm quyền kiểm soát. Anthropic xây dựng hệ thống phòng thủ đa lớp để đối phó với cả ba mối đe dọa này.
Lạm dụng của người dùng bao gồm nhiều hình thức. Một người dùng có thể cố ý yêu cầu AI làm điều gì đó có hại. Hoặc họ có thể vô tình chạy một lệnh nguy hiểm mà không hiểu rõ. Việc giáo dục người dùng là quan trọng, nhưng không thể là tuyến phòng thủ duy nhất. Trọng tâm của Anthropic là xây dựng các hệ thống có khả năng chống lại sự lạm dụng này, ngay cả khi người dùng mắc lỗi.
Mô hình hoạt động sai là một rủi ro cố hữu của công nghệ AI hiện tại. Các mô hình có thể "ảo giác" hoặc thực hiện các hành động không lường trước được. Việc huấn luyện an toàn và các kỹ thuật như Constitutional AI giúp giảm thiểu rủi ro này. Tuy nhiên, không có gì đảm bảo 100% hiệu quả. Theo Anthropic Engineering (2026), các biện pháp phòng thủ có thể giữ tỷ lệ tấn công thành công ở mức 0.1% cho một lần thử. Nhưng con số này có thể tăng lên 5-6% sau 100 lần thử thích ứng.
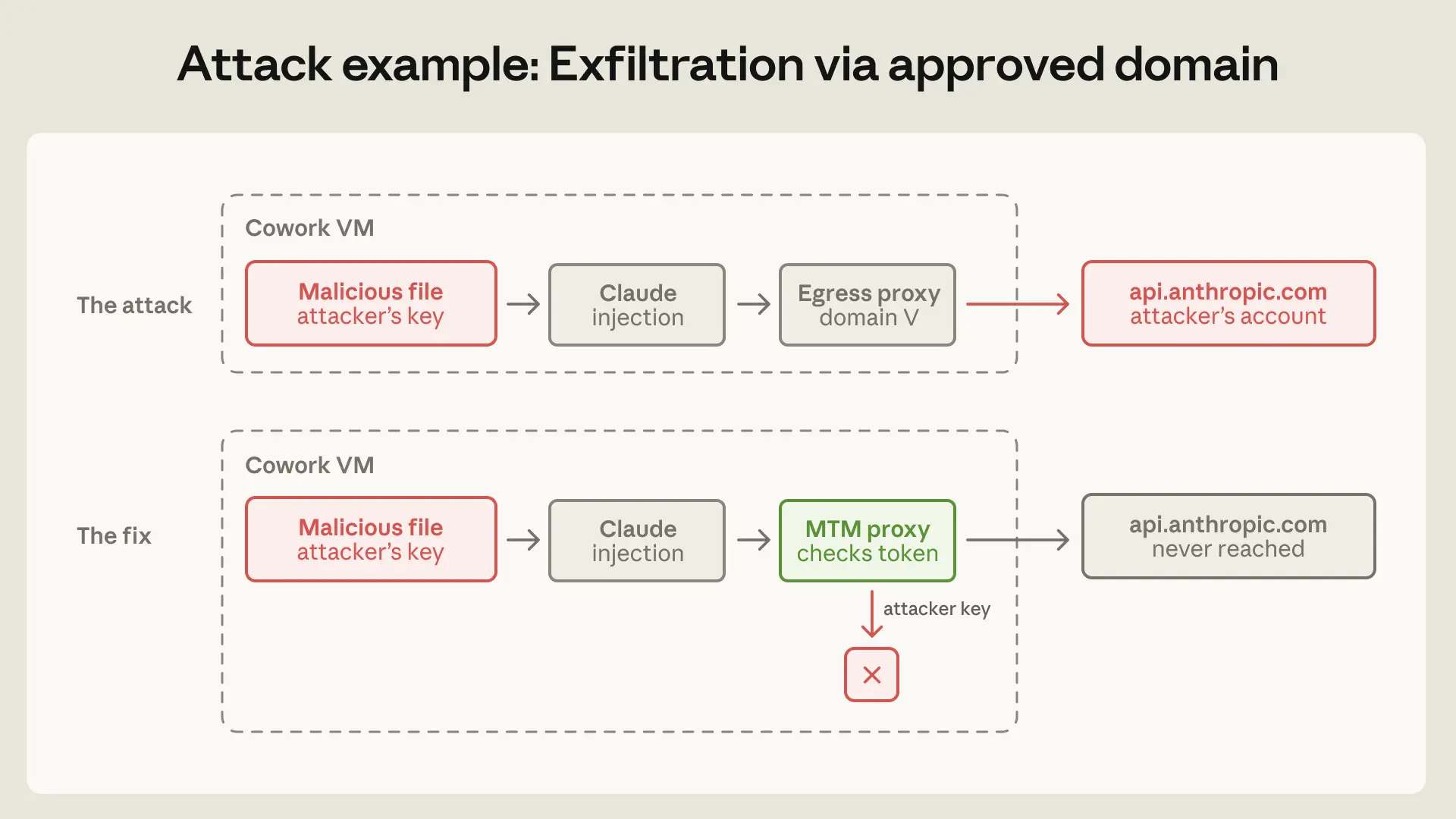
Cuối cùng, tấn công từ bên ngoài là mối đe dọa nghiêm trọng. Các kỹ thuật như "jailbreaking" hay "prompt injection" có thể khiến AI bỏ qua các biện pháp an toàn của nó. Đây là lý do tại sao các lớp kiểm soát bên ngoài (containment) lại cực kỳ quan trọng. Chúng hoạt động như một bức tường lửa, ngăn chặn AI gây hại ngay cả khi lớp phòng thủ bên trong bị xuyên thủng. Theo StartupHub.ai (2026), việc tập trung vào an toàn AI đã là tôn chỉ của Anthropic ngay từ khi được thành lập bởi các nhà nghiên cứu Dario và Daniela Amodei.
Tương lai của việc kiểm soát AI sẽ là sự kết hợp của nhiều yếu tố. Đó là các mô hình được thiết kế an toàn hơn từ gốc. Đó là các lớp phòng thủ bên ngoài ngày càng tinh vi. Và đó là các tiêu chuẩn ngành rõ ràng hơn. Việc kiểm soát sẽ là nỗ lực chung của toàn bộ hệ sinh thái, từ nhà phát triển AI đến người dùng cuối.
Phòng thủ theo chiều sâu (defense-in-depth) sẽ vẫn là triết lý chủ đạo. Không một lớp bảo vệ đơn lẻ nào là hoàn hảo. Sự kết hợp giữa an toàn ở cấp độ mô hình, giám sát hành vi thông minh và kiểm soát môi trường nghiêm ngặt sẽ tạo ra một hệ thống vững chắc. Theo Anthropic Engineering (2026), ngay cả những biện pháp phòng thủ tốt nhất cũng không thể hiệu quả 100%. Vì vậy, các lớp bảo vệ không thể đứng một mình.
Một xu hướng quan trọng là tự động hóa các biện pháp an toàn. Thay vì làm phiền người dùng với các cảnh báo liên tục, hệ thống sẽ tự động xử lý các rủi ro ở mức độ cao. Chế độ tự động của Claude Code là một ví dụ điển hình. Theo Anthropic Engineering (2026), chế độ này đã bắt được khoảng 83% các hành vi quá khích trước khi chúng được thực thi. Điều này giúp giảm gánh nặng cho người dùng và tăng hiệu quả bảo vệ.
Cuối cùng, sự hợp tác và minh bạch sẽ đóng vai trò then chốt. Việc chia sẻ các bài học kinh nghiệm, như Anthropic đang làm, giúp toàn ngành cùng nhau tiến bộ. Việc phát hành các công cụ nguồn mở cũng góp phần xây dựng các tiêu chuẩn chung. Tương lai của AI an toàn phụ thuộc vào khả năng của chúng ta trong việc xây dựng và duy trì các hệ thống kiểm soát hiệu quả.
Nghiên cứu này khám phá khả năng tạo ra một 'nút tắt' để vô hiệu hóa kiến thức lưỡng dụng trong các mô hình AI. Mục tiêu là kiểm soát và ngăn chặn việc AI sử dụng thông tin có thể gây hại, đảm bảo an toàn và đạo đức trong phát triển trí tuệ nhân tạo.
09/07/2026
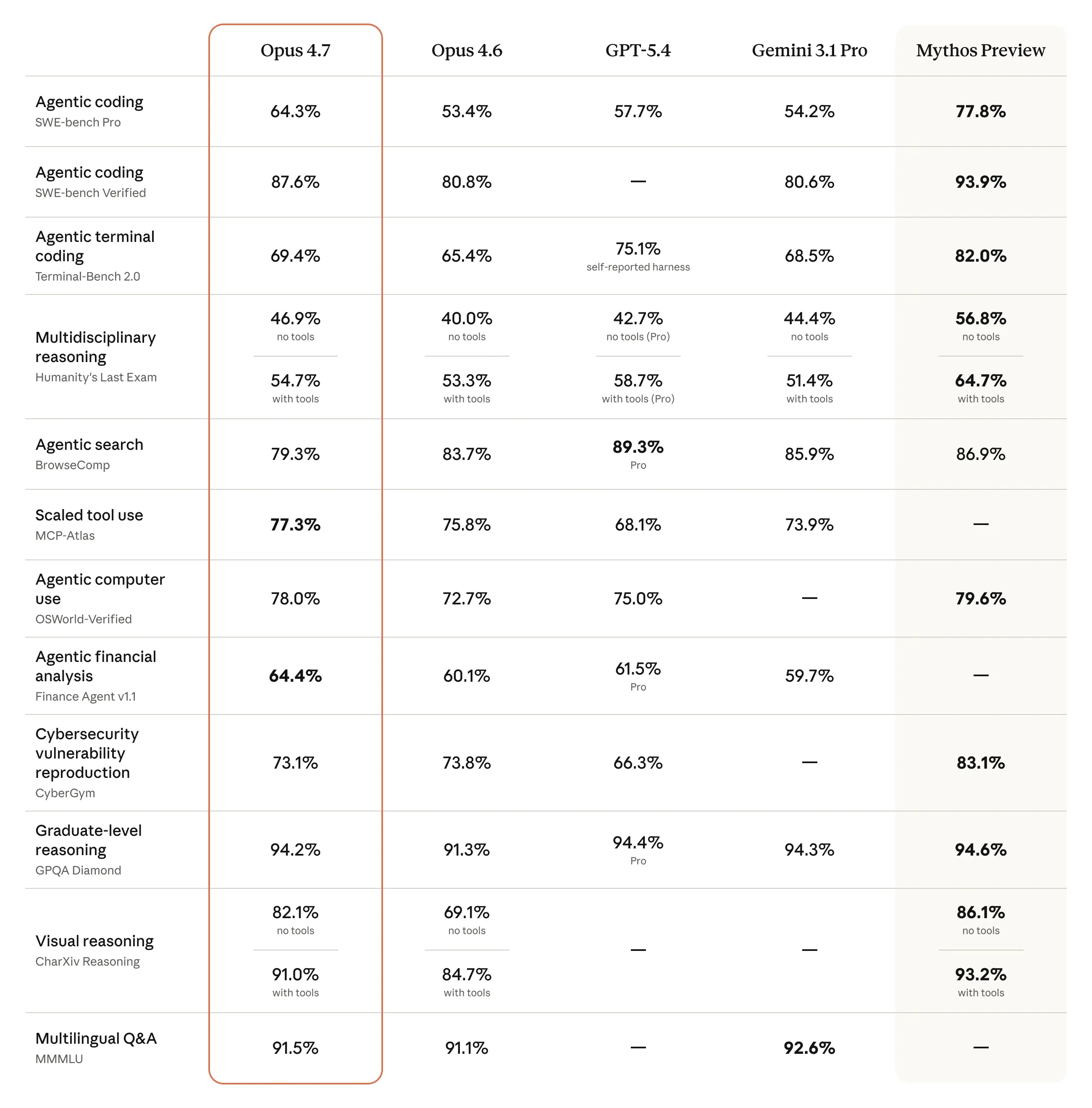
Anthropic vừa ra mắt Claude Opus 4.7, một phiên bản cải tiến đáng kể so với Opus 4.6, đặc biệt trong lĩnh vực kỹ thuật phần mềm và khả năng thị giác. Mô hình này có thể xử lý các tác vụ mã hóa phức tạp, chú ý đến hướng dẫn và tự kiểm tra đầu ra. Opus 4.7 cũng tích hợp các biện pháp bảo vệ an ninh mạng tiên tiến, đồng thời duy trì mức giá như phiên bản trước.
04/05/2026

Anthropic và Amazon vừa công bố mở rộng hợp tác chiến lược, một bước đi quan trọng trong cuộc đua AI. Với cam kết hạ tầng trị giá 100 tỷ USD và khoản đầu tư lên tới 25 tỷ USD từ Amazon, Anthropic sẽ có thêm 5 gigawatt năng lực tính toán. Thỏa thuận này không chỉ củng cố vị thế của Claude trên nền tảng AWS mà còn hứa hẹn nâng cao hiệu suất và khả năng tiếp cận cho người dùng toàn cầu.
04/05/2026