Dự án Glasswing của Anthropic, với sự tham gia của 50 đối tác, đã sử dụng AI Claude Mythos Preview để phát hiện hơn mười nghìn lỗ hổng bảo mật nghiêm trọng. Cập nhật ban đầu này cho thấy tiềm năng to lớn của AI trong việc bảo vệ phần mềm quan trọng, đồng thời đặt ra thách thức mới về việc xác minh và vá lỗi ở quy mô lớn.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Anthropic Research →
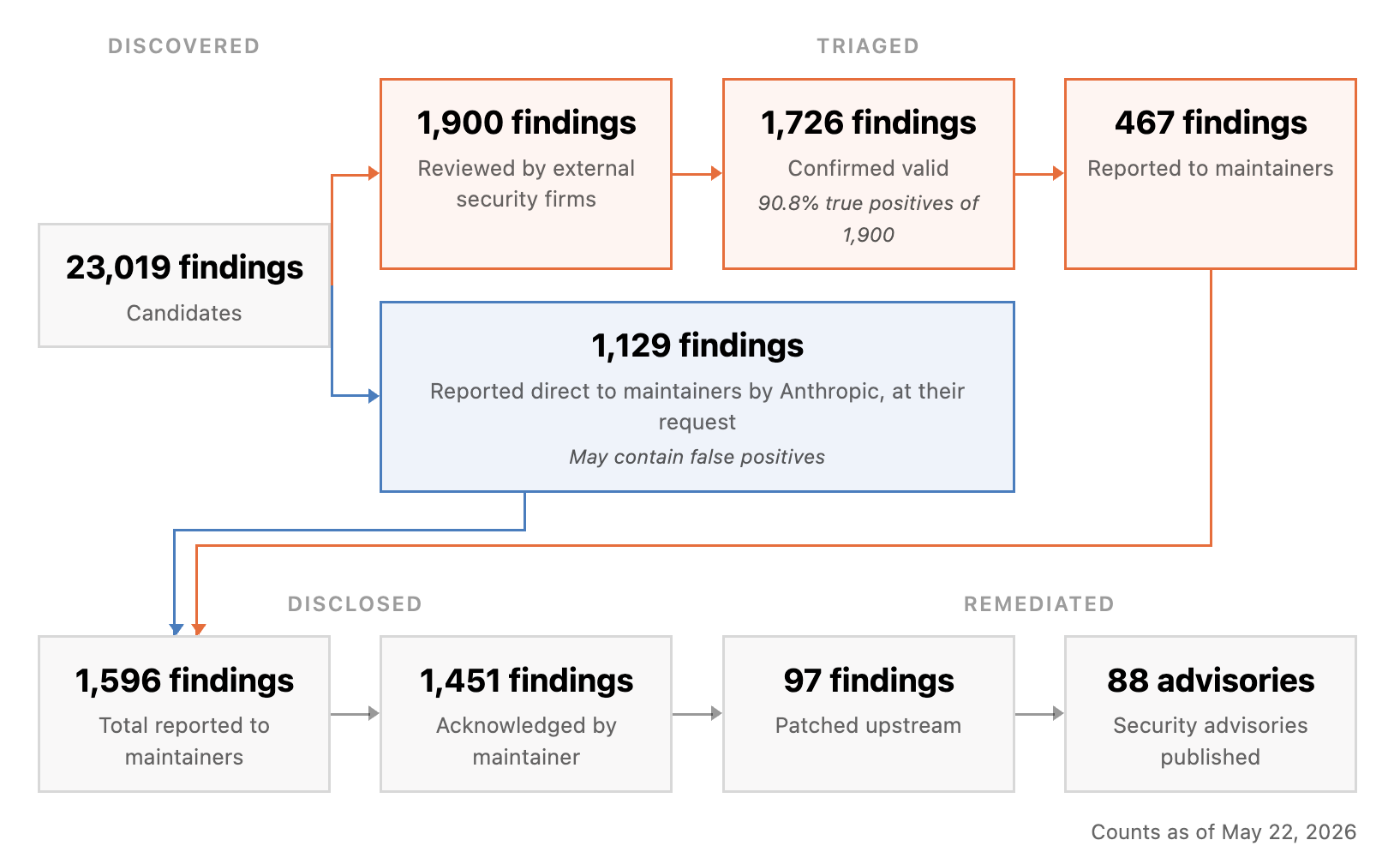
Dự án Glasswing là một nỗ lực hợp tác do Anthropic khởi xướng cùng khoảng 50 đối tác. Mục tiêu chính là sử dụng trí tuệ nhân tạo tiên tiến, cụ thể là mô hình Claude Mythos Preview, để tìm và vá các lỗ hổng trong những phần mềm quan trọng nhất thế giới. Dự án này nhằm mục đích bảo vệ cơ sở hạ tầng kỹ thuật số trước khi các mô hình AI mạnh hơn bị lạm dụng cho mục đích tấn công.
Glasswing ra đời từ nhận thức rằng cuộc đua an ninh mạng đang thay đổi. Khi AI ngày càng có năng lực, nguy cơ chúng bị sử dụng để tự động tìm và khai thác lỗ hổng cũng tăng lên. Thay vì chờ đợi các cuộc tấn công xảy ra, Anthropic đã chủ động tạo ra một liên minh phòng thủ. Các đối tác bao gồm những tên tuổi lớn như Cloudflare, Google, và Microsoft. Theo Futurum Group (2026), Anthropic đã cam kết 100 triệu USD tín dụng sử dụng mô hình cho những người tham gia Glasswing. Điều này cho thấy sự đầu tư nghiêm túc vào việc xây dựng một hệ sinh thái an toàn. Theo Anthropic Research (2026), mục tiêu là bảo vệ phần mềm quan trọng nhất thế giới trước khi các mô hình AI có năng lực cao hơn có thể bị lạm dụng để tấn công chúng.


Chỉ sau một tháng, Claude Mythos Preview đã giúp các đối tác phát hiện hơn mười nghìn lỗ hổng bảo mật ở mức độ cao hoặc nghiêm trọng. Một số đối tác báo cáo rằng tốc độ tìm lỗi của họ đã tăng gấp mười lần. Kết quả này cho thấy một bước tiến vượt bậc, chứng tỏ khả năng của AI trong việc tự động hóa và mở rộng quy mô săn lùng lỗ hổng bảo mật.
Các con số cụ thể rất ấn tượng. Ví dụ, Cloudflare đã tìm thấy 2.000 lỗi trong các hệ thống quan trọng của họ, với 400 lỗi được xếp hạng cao hoặc nghiêm trọng. Đáng chú ý, đội ngũ của Cloudflare nhận định tỷ lệ dương tính giả của Mythos Preview còn tốt hơn cả chuyên gia con người. Theo Anthropic Research (2026), trong số các lỗ hổng được báo cáo và xác minh, 90.6% là dương tính thật và 62.4% được xác nhận là nghiêm trọng. Hiệu suất của mô hình cũng được chứng minh qua các bài kiểm tra tiêu chuẩn. Trên benchmark CyberGym năm 2026, Mythos Preview đạt 83.1% điểm, vượt xa con số 66.6% của Claude Opus 4.6.


Thách thức lớn nhất hiện nay không còn là việc tìm ra lỗ hổng, mà là quá trình xác minh, tiết lộ và vá chúng một cách hiệu quả. Tốc độ phát hiện của AI đã vượt xa khả năng xử lý của con người, tạo ra một "nút thắt cổ chai" nghiêm trọng trong khâu phân loại và khắc phục. Vấn đề này đòi hỏi sự thay đổi trong quy trình quản lý lỗ hổng.
Anthropic gọi đây là "vấn đề 1%". Theo Futurum Group (2026), chưa đến 1% trong số hàng nghìn lỗ hổng mà Mythos Preview phát hiện đã được vá. Con số này không phản ánh sự chậm trễ mà là quy mô tuyệt đối của vấn đề. Mỗi lỗ hổng cần được chuyên gia con người xem xét, xác thực, ưu tiên và phát triển bản vá. Khi số lượng lỗ hổng tăng đột biến, quy trình hiện tại trở nên quá tải. Theo Forrester (2026), tình huống này phơi bày những hậu quả tiềm tàng đối với hoạt động của các đội an ninh mạng, đòi hỏi họ phải suy nghĩ lại về cách phân bổ nguồn lực.


Anthropic tuân thủ nghiêm ngặt chính sách Tiết lộ Lỗ hổng Phối hợp (Coordinated Vulnerability Disclosure). Theo quy ước ngành, họ thường đợi 90 ngày sau khi phát hiện lỗ hổng mới công bố chi tiết. Khoảng thời gian này rất quan trọng. Nó cho phép các nhà phát triển tạo bản vá và người dùng cuối có đủ thời gian để cập nhật phần mềm, giảm thiểu rủi ro bị tấn công.
Do chính sách này, các lỗ hổng được công bố là một chỉ báo có độ trễ về khả năng thực sự của AI. Anthropic chưa thể chia sẻ toàn bộ chi tiết về những gì Mythos Preview đã tìm thấy mà không gây rủi ro cho người dùng. Thay vào đó, họ cung cấp các ví dụ minh họa và số liệu thống kê tổng hợp. Theo chính sách của Anthropic (2026), cách tiếp cận này cân bằng giữa việc chia sẻ tiến bộ nghiên cứu và trách nhiệm bảo vệ cộng đồng. Điều này cũng phù hợp với bối cảnh rộng hơn, khi một khảo sát năm 2026 của Futurum Group cho thấy 78% CIO coi quản trị và bảo mật là rào cản hàng đầu khi áp dụng AI.

Anthropic sẽ tiếp tục mở rộng Glasswing, tập trung vào việc giải quyết nút thắt cổ chai trong khâu vá lỗi. Họ không có kế hoạch phát hành rộng rãi Mythos Preview cho công chúng. Thay vào đó, các mô hình tương lai sẽ được tích hợp các biện pháp bảo vệ để ngăn chặn lạm dụng và chỉ được cung cấp cho các đối tác tin cậy trong môi trường được kiểm soát.
Mục tiêu dài hạn không chỉ là tìm lỗi, mà là hỗ trợ các chuyên gia phòng thủ mạng (cyberdefenders) sửa lỗi hiệu quả hơn. Theo Anthropic Research (2026), công ty đang tích cực nghiên cứu các giải pháp bền vững để tích hợp AI vào toàn bộ vòng đời an ninh mạng. Hiệu suất vượt trội của Mythos Preview trên các benchmark lập trình, như đạt 77.8% trên SWE-bench Pro năm 2026, cho thấy tiềm năng của nó không chỉ trong việc tìm lỗi mà còn trong việc gợi ý cách sửa lỗi. Việc phát hành có kiểm soát nhằm đảm bảo công nghệ mạnh mẽ này được sử dụng một cách có trách nhiệm.
Nhóm Frontier Red Team của Anthropic đã công bố LLM ATT&CK Navigator, một công cụ đột phá để lập bản đồ các mối đe dọa an ninh mạng do AI gây ra. Bằng cách điều chỉnh khuôn khổ MITRE ATT&CK nổi tiếng cho các mô hình ngôn ngữ lớn, nghiên cứu này cung cấp một cái nhìn sâu sắc về cách các tác nhân độc hại có thể khai thác AI và quan trọng hơn là cách chúng ta có thể xây dựng hệ thống phòng thủ chủ động để chống lại chúng.
17/06/2026

Anthropic đang phát triển Claude để trở thành một công cụ mạnh mẽ cho ngành hóa học. Bằng cách tận dụng khả năng đa phương thức và suy luận tường minh, Claude có thể phân tích dữ liệu phức tạp như phổ NMR, vượt qua các phần mềm chuyên dụng và hứa hẹn đẩy nhanh tốc độ khám phá khoa học trong phòng thí nghiệm.
06/06/2026

Anthropic đang mở rộng đáng kể Dự án Glasswing, một nỗ lực hợp tác nhằm bảo vệ các phần mềm quan trọng nhất thế giới bằng AI. Với việc bổ sung 150 tổ chức từ hơn 15 quốc gia, dự án tập trung vào các lĩnh vực hạ tầng trọng yếu. Sáng kiến này sử dụng mô hình Claude Mythos Preview để chủ động phát hiện lỗ hổng, chuẩn bị cho một kỷ nguyên mới của an ninh mạng.
04/06/2026
