Tốc độ cải tiến nhanh chóng của các mô hình ngôn ngữ lớn đặt ra câu hỏi về khả năng căn chỉnh và giám sát các mô hình AI thông minh hơn con người. Một nghiên cứu mới của Anthropic khám phá cách Claude có thể tự động phát triển, thử nghiệm và phân tích các ý tưởng căn chỉnh, đặc biệt trong vấn đề giám sát từ yếu đến mạnh. Kết quả cho thấy Claude có thể vượt trội đáng kể so với hiệu suất của con người trong việc phục hồi khoảng cách hiệu suất.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Anthropic Research →
Anthropic nhấn mạnh rằng quyền truy cập của các tác nhân AI phải phát triển cùng với khả năng của chúng. Bằng cách sử dụng kỹ thuật "sandboxing", công ty tạo ra các môi trường biệt lập để thực thi mã lệnh, giới hạn phạm vi của bất kỳ hành động nào có khả năng gây hại và đảm bảo an toàn cho người dùng và hệ thống.
26/05/2026

Anthropic đang kêu gọi mở rộng cuộc đối thoại về AI tiên tiến, không chỉ giới hạn trong giới công nghệ. Bằng cách tham vấn các nhà triết học, giáo sĩ và nhà đạo đức học, họ tìm cách định hình "tính cách" cho Claude, đảm bảo AI phát triển an toàn, có trách nhiệm và thực sự phục vụ lợi ích toàn cầu.
22/05/2026

Research powered by Tavily.
Sự kiện Jan Leike, một trong những nhà nghiên cứu an toàn AI hàng đầu, gia nhập Anthropic đang tạo ra làn sóng trong ngành. Dự án mới của anh không chỉ tập trung vào 'căn chỉnh' mà còn hướng tới một cách tiếp cận toàn diện hơn để đảm bảo Trí tuệ tổng quát nhân tạo (AGI) phát triển an toàn và có lợi cho nhân loại. Điều này đánh dấu một chương mới đầy hứa hẹn cho Anthropic.
14/05/2026
Tốc độ cải tiến nhanh chóng của các mô hình ngôn ngữ lớn đặt ra câu hỏi về khả năng căn chỉnh và giám sát các mô hình AI thông minh hơn con người. Một nghiên cứu mới của Anthropic khám phá cách Claude có thể tự động phát triển, thử nghiệm và phân tích các ý tưởng căn chỉnh, đặc biệt trong vấn đề giám sát từ yếu đến mạnh. Kết quả cho thấy Claude có thể vượt trội đáng kể so với hiệu suất của con người trong việc phục hồi khoảng cách hiệu suất.
Tốc độ cải tiến ngày càng nhanh của các mô hình ngôn ngữ lớn đặt ra hai câu hỏi đặc biệt quan trọng cho nghiên cứu về căn chỉnh (alignment).
Một là làm thế nào để việc căn chỉnh có thể theo kịp. Các mô hình AI tiên tiến hiện đang đóng góp vào sự phát triển của những mô hình kế nhiệm. Nhưng liệu chúng có thể mang lại sự nâng cao tương tự cho các nhà nghiên cứu căn chỉnh không? Liệu các mô hình ngôn ngữ của chúng ta có thể được sử dụng để giúp tự căn chỉnh chúng không?
Câu hỏi thứ hai là chúng ta sẽ làm gì khi các mô hình trở nên thông minh hơn chúng ta. Căn chỉnh các mô hình AI thông minh hơn con người là một lĩnh vực nghiên cứu được gọi là “giám sát có thể mở rộng” (scalable oversight). Giám sát có thể mở rộng phần lớn đã được thảo luận dưới dạng lý thuyết, hơn là thực tế — nhưng với tốc độ cải tiến hiện tại của AI, điều đó có thể sẽ không còn đúng trong thời gian dài nữa. Ví dụ, các mô hình đã và đang tạo ra một lượng lớn mã. Nếu kỹ năng của chúng phát triển đến mức chúng tạo ra hàng triệu dòng mã cực kỳ phức tạp mà chúng ta không thể tự phân tích, thì có thể trở nên rất khó để biết liệu chúng có đang hành động theo cách chúng ta mong muốn hay không.
Trong một nghiên cứu mới của Anthropic Fellows, chúng tôi theo đuổi cả hai câu hỏi này.
Nghiên cứu mới của chúng tôi tập trung vào một vấn đề được gọi là “giám sát từ yếu đến mạnh” (weak-to-strong supervision), một vấn đề phản ánh việc giám sát các mô hình AI thông minh hơn con người. Chúng tôi bắt đầu với một “mô hình cơ sở” (base model) tương đối mạnh — tức là một mô hình có khả năng tiềm tàng nhưng chưa được tinh chỉnh để đưa ra câu trả lời tốt nhất có thể. Sau đó, chúng tôi sử dụng một mô hình yếu hơn nhiều làm “giáo viên” để cung cấp sự tinh chỉnh bổ sung đó, bằng cách trình bày những gì nó coi là đầu ra lý tưởng cho mô hình cơ sở mạnh. Cuối cùng, chúng tôi đánh giá mức độ hoạt động của mô hình mạnh sau quá trình tinh chỉnh yếu đó.
Trong trường hợp xấu nhất, mô hình mạnh sẽ chỉ tốt bằng giáo viên yếu của nó. Tuy nhiên, lý tưởng nhất là mô hình mạnh sẽ học được từ phản hồi của giáo viên yếu — nó sẽ diễn giải các tín hiệu yếu đó một cách hữu ích, sử dụng phản hồi đó để cải thiện hiệu suất của mình. Chúng ta có thể định lượng mức độ nó đã làm được điều đó: nếu mô hình mạnh không cho thấy bất kỳ sự cải thiện nào (nó chỉ hoạt động tốt bằng giáo viên yếu của nó), chúng tôi chấm điểm 0; nếu nó sử dụng phản hồi của giáo viên để đạt được kết quả lý tưởng — hiệu suất tốt nhất mà mô hình mạnh có thể mang lại — chúng tôi chấm điểm 1. Thước đo này đại diện cho “khoảng cách hiệu suất được phục hồi” (performance gap recovered) (giữa mô hình yếu và giới hạn trên của mô hình mạnh), hay PGR.
Là một đại diện cho giám sát có thể mở rộng, mô hình yếu đại diện cho con người, và mô hình mạnh đại diện cho các mô hình thông minh hơn con người rất nhiều mà một ngày nào đó chúng ta có thể cần giám sát. Nếu chúng ta có thể đạt được tiến bộ trong giám sát từ yếu đến mạnh, chúng ta có thể thấy rằng các phương pháp của chúng ta giúp chúng ta giữ cho các mô hình siêu thông minh đó phù hợp với các giá trị của chúng ta.
Nghiên cứu mới của chúng tôi kiểm tra xem Claude có thể tự động khám phá các cách để cải thiện PGR hay không. Chúng tôi đặt câu hỏi: liệu Claude có thể phát triển, thử nghiệm và phân tích các ý tưởng căn chỉnh của riêng mình không? Và, nếu có thể, điều đó có thể ngụ ý gì về mức độ các mô hình AI hiện nay có thể tăng tốc nghiên cứu căn chỉnh?
Để tìm hiểu, chúng tôi bắt đầu với chín bản sao của Claude Opus 4.6, và cung cấp cho mỗi bản một vài công cụ bổ sung. Mỗi Claude có một nơi để làm việc và suy nghĩ (tức là một môi trường thử nghiệm), một diễn đàn chung để chia sẻ phát hiện của mình với những người khác, một hệ thống lưu trữ để tải mã của mình lên, và một máy chủ từ xa nơi nó có thể nhận điểm PGR cho mỗi ý tưởng của mình. Chúng tôi cũng cung cấp một số kiến thức nền tảng về đào tạo và suy luận mô hình. Chúng tôi gọi các mô hình Claude được trang bị công cụ này là Các Nhà Nghiên Cứu Căn Chỉnh Tự Động (hoặc AARs).
Để ngăn mỗi AAR theo đuổi các ý tưởng gần như giống hệt nhau, chúng tôi đã gợi ý cho mỗi AAR một điểm khởi đầu hơi khác (nhưng cố ý mơ hồ): chúng tôi khuyến nghị một AAR sử dụng một số công cụ giải thích, một AAR khác suy nghĩ về việc điều chỉnh trọng số dữ liệu trong tập dữ liệu, v.v.1 Ngoài ra, chúng tôi không nói cho các AAR biết phải làm gì. Tùy thuộc vào chúng để đề xuất ý tưởng của riêng mình, chạy thử nghiệm, phân tích kết quả và chia sẻ phát hiện cũng như mã của mình với nhau để tìm ra điều cần thử tiếp theo.
Để cung cấp một tiêu chuẩn cho kết quả của AARs, chúng tôi đã so sánh công việc của chúng với mức cơ sở của con người. Hai trong số các nhà nghiên cứu của chúng tôi đã dành bảy ngày để lặp lại bốn phương pháp khái quát hóa hứa hẹn nhất từ nghiên cứu trước đây. Trên các mô hình mã nguồn mở mà chúng tôi đã thử nghiệm (Qwen 3-4B-Base làm mô hình mạnh, Qwen 1.5-0.5B-Chat làm giáo viên yếu), con người đã phục hồi 23% tổng khoảng cách hiệu suất (tức là đạt PGR 0.23).2
Claude đã cải thiện đáng kể kết quả này. Sau năm ngày nữa (và 800 giờ nghiên cứu tích lũy), các AAR đã thu hẹp gần như toàn bộ khoảng cách hiệu suất còn lại, đạt PGR cuối cùng là 0.97. Chi phí này khoảng 18.000 đô la cho token và chi phí đào tạo mô hình, hoặc 22 đô la mỗi giờ AAR. Bạn có thể xem cách mỗi AAR riêng lẻ tiến bộ từ mức cơ sở của con người (ở 0 giờ) trong biểu đồ dưới đây.
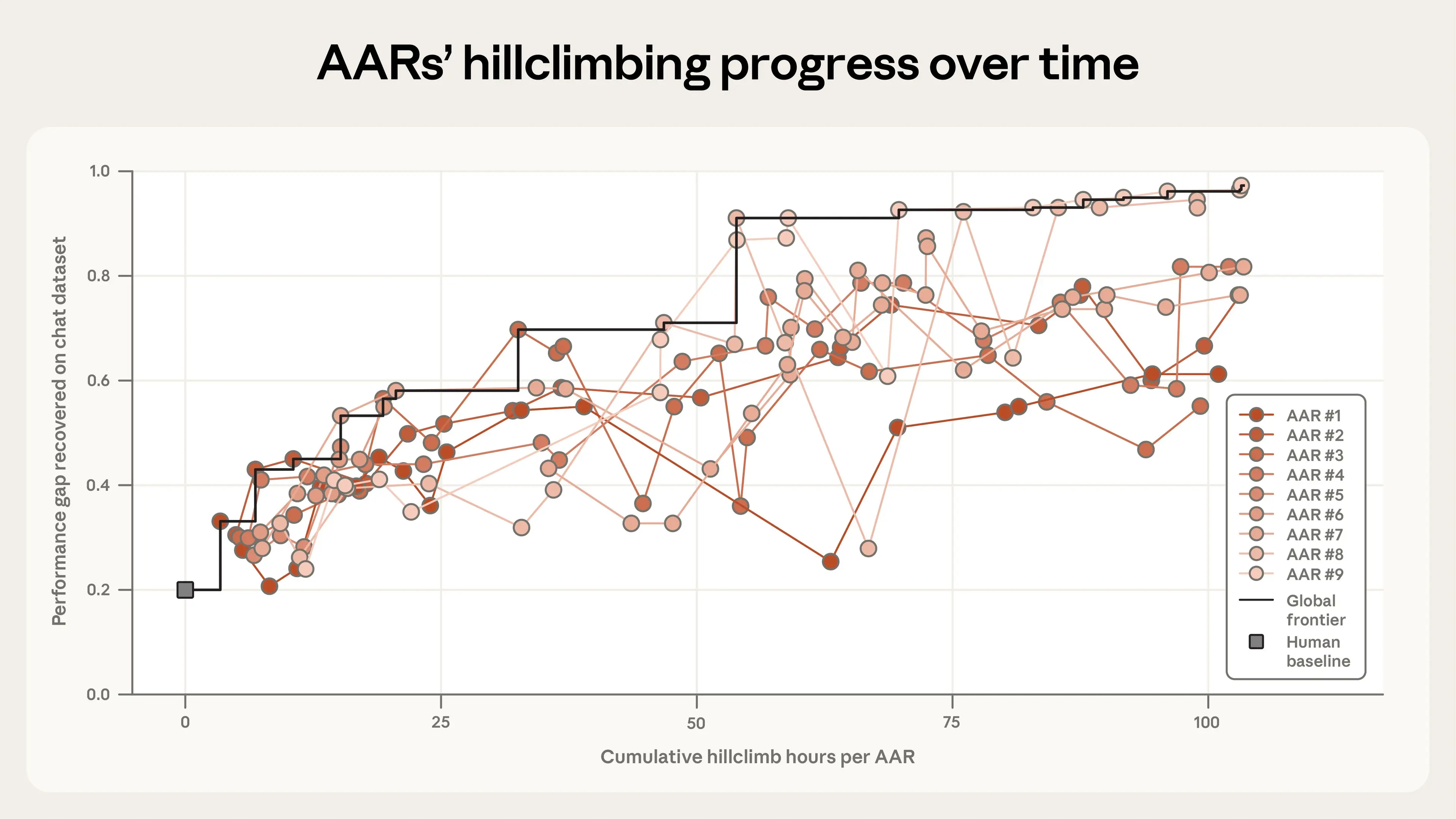
Khoảng cách hiệu suất được phục hồi theo giờ nghiên cứu tích lũy cho chín Nhà Nghiên Cứu Căn Chỉnh Tự Động song song (đường màu đỏ), so với mức cơ sở được tinh chỉnh bởi con người (ô vuông màu xám). Điểm 1.0 có nghĩa là phương pháp hoàn toàn khớp với một mô hình được đào tạo trên nhãn ground-truth.
Claude, sau đó, đã làm rất tốt. Nhưng các phương pháp của nó có sáng tạo đến mức nào, và liệu chúng có thể hữu ích trong các ứng dụng thực tế không? Để tìm hiểu, chúng tôi đã chạy thêm hai thử nghiệm.
Đầu tiên, chúng tôi đã kiểm tra xem các ý tưởng của AARs có thể phục hồi khoảng cách hiệu suất trên các tập dữ liệu chưa từng thấy (held-out datasets) hay không — tức là trên các tác vụ mà AARs chưa từng thấy. Chúng tôi lấy hai phương pháp hoạt động tốt nhất của AARs (trên một tập dữ liệu các tác vụ trò chuyện) và áp dụng chúng cho các tác vụ toán học và lập trình. Ở đây, kết quả của chúng tôi khá hứa hẹn: phương pháp hiệu quả nhất của AARs đã khái quát hóa thành công cho cả hai tập dữ liệu mới, với PGR là 0.94 cho toán học và 0.47 cho lập trình (vẫn gấp đôi mức cơ sở của con người). Phương pháp tốt thứ hai của AARs cho thấy kết quả trái chiều: nó hoạt động tốt trên toán học (0.75), nhưng không hoạt động trên mã, nơi nó làm cho mọi thứ tồi tệ hơn. Những kết quả này cho thấy rằng một số khả năng khái quát hóa trong nghiên cứu của AARs là có thể, nhưng không phải là điều hiển nhiên. Chúng tôi khuyến khích những người khác thử nghiệm nghiên cứu tự động cũng nên kiểm tra kỹ các ý tưởng của AARs đối với các tập dữ liệu chưa từng thấy.
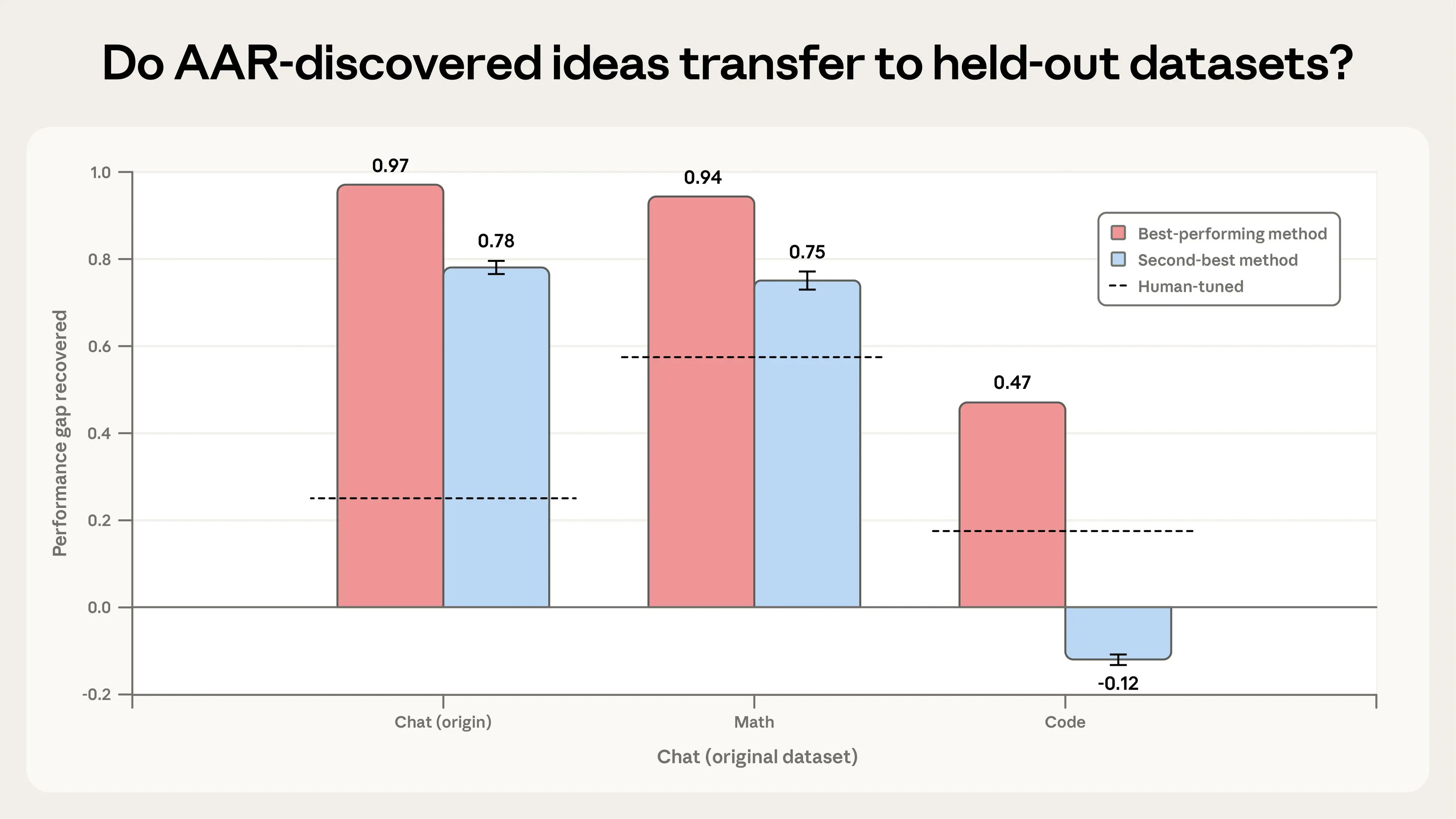
Khoảng cách hiệu suất được phục hồi bởi hai ý tưởng do AAR phát hiện (màu đỏ và xanh lam) khi áp dụng cho các tập dữ liệu toán học và mã hóa chưa từng thấy. Đường đứt nét chỉ ra phương pháp tinh chỉnh tốt nhất của con người mà chúng tôi đã sử dụng làm mức cơ sở.
Tiếp theo, chúng tôi đã kiểm tra xem các ý tưởng của AARs có hoạt động ở quy mô sản xuất hay không. Chúng tôi đã thử phương pháp hiệu quả nhất của AARs trên Claude Sonnet 4 với cơ sở hạ tầng đào tạo sản xuất của chúng tôi. Tuy nhiên, ở đây, chúng tôi ít thành công hơn. Phương pháp của AARs không dẫn đến một cải thiện có ý nghĩa thống kê. Chúng tôi nghĩ rằng điều này có thể phản ánh những hạn chế của thử nghiệm ban đầu này, hơn là một điều gì đó cơ bản hơn: phương pháp chấm điểm của chúng tôi khá đơn giản, và chúng tôi chỉ đánh giá một ý tưởng duy nhất. Tuy nhiên, điều này minh họa một hạn chế của AARs (ít nhất là ở khả năng hiện tại của chúng): AARs có xu hướng tận dụng các cơ hội độc đáo cho các mô hình và tập dữ liệu mà chúng được cung cấp, điều đó có nghĩa là các phương pháp của chúng có thể không hoạt động ở những nơi khác. Để giảm thiểu điều này, chúng tôi đề xuất cho phép AARs thử nghiệm trên nhiều miền và tập dữ liệu trong quá trình nghiên cứu của chúng. Đây là một lĩnh vực mà các thử nghiệm trong tương lai với AARs có thể khám phá.
Một vài lần lặp lại thử nghiệm của chúng tôi đã dạy chúng tôi nhiều hơn về cách làm cho AARs hiệu quả nhất. Ví dụ, chúng tôi thấy rằng việc cung cấp cho mỗi AAR một điểm khởi đầu khác nhau đã giúp ích rất nhiều, ngay cả khi điểm khởi đầu đó mơ hồ. Khi chúng tôi thử nghiệm mà không định hướng các AAR theo các hướng khác nhau, tất cả chúng đều nhanh chóng đi đến những ý tưởng tương tự, đạt được ít tiến bộ hơn nhiều (mặc dù chúng vẫn đạt PGR gần gấp ba lần mức cơ sở của con người). Mặt khác, chúng tôi thấy rằng việc cung cấp cho AARs quá nhiều cấu trúc đã làm tổn hại nghiêm trọng đến tiến độ của chúng. Khi chúng tôi quy định một quy trình làm việc cụ thể (“đề xuất ý tưởng, sau đó lập kế hoạch, sau đó viết mã…”), chúng tôi thấy rằng cuối cùng chúng tôi đã hạn chế công việc của Claude. Khi được tự do, Claude thích nghi hơn nhiều, thiết kế các thử nghiệm rẻ tiền để kiểm tra ý tưởng của mình trước khi cam kết thử nghiệm chuyên sâu hơn nhiều.
Thành công của các AAR của chúng tôi trong việc phục hồi khoảng cách hiệu suất giữa hai mô hình mã nguồn mở chắc chắn không phải là dấu hiệu cho thấy các mô hình AI tiên tiến hiện là các nhà khoa học căn chỉnh đa năng. Chúng tôi cố tình chọn một vấn đề đặc biệt phù hợp với tự động hóa, vì nó có một thước đo thành công duy nhất, khách quan mà các mô hình có thể tối ưu hóa. Hầu hết các vấn đề căn chỉnh không gọn gàng như vấn đề này. Và, như chúng tôi đề cập dưới đây, ngay cả trong môi trường này, các AAR của chúng tôi đã cố gắng hết sức để “lách luật” vấn đề: sự giám sát của con người vẫn là điều cần thiết.
Nhưng chúng tôi nghĩ rằng những kết quả này có một số ý nghĩa quan trọng.
Theo kịp tốc độ. Nghiên cứu này chỉ ra rằng Claude có thể tăng đáng kể tốc độ thử nghiệm và khám phá trong nghiên cứu căn chỉnh. Các nhà nghiên cứu con người có thể giao các câu hỏi cho AARs ở quy mô rất lớn; Claude có thể đảm nhận nhiệm vụ phát triển các giả thuyết mới và lặp lại trên kết quả của chính mình.
Hơn nữa, việc đạt được tiến bộ trong giám sát từ yếu đến mạnh bản thân nó có thể giúp chúng ta xây dựng các Nhà Nghiên Cứu Căn Chỉnh Tự Động đa năng hơn, đó là lý do tại sao chúng tôi chọn vấn đề này cho nghiên cứu của mình. Trong nghiên cứu này, chúng tôi định hình vấn đề giám sát từ yếu đến mạnh như một tác vụ “rõ ràng” với kết quả có thể kiểm chứng (tăng điểm PGR). Chúng tôi làm điều này vì chúng tôi cần một cách để tự động và đáng tin cậy đánh giá xem AAR đã đạt được tiến bộ hay chưa. Tuy nhiên, nếu AARs khám phá ra các phương pháp giám sát từ yếu đến mạnh tốt hơn nhiều và có thể khái quát hóa trên các miền, chúng ta có thể sử dụng các phương pháp đó để đào tạo AARs đánh giá tiến độ trên các tác vụ “mơ hồ” hơn, khó kiểm chứng hơn nhiều. (Ví dụ, chúng ta có thể thực hiện giám sát từ yếu đến mạnh về khả năng của Claude trong việc xác định phạm vi các dự án nghiên cứu.) Điều này quan trọng, bởi vì nghiên cứu căn chỉnh — không giống như nghiên cứu về khả năng — thường đòi hỏi phải giải quyết các vấn đề “mơ hồ” hơn nhiều.
Gu và sự đa dạng. Một phản biện có thể có đối với các công cụ như AARs là các mô hình tiên tiến hiện nay vẫn thiếu “gu nghiên cứu” (thuật ngữ trong ngành để chỉ khả năng trực giác về ý tưởng nào có thể hoạt động và ý tưởng nào không). Nhưng thành công của AARs trong thử nghiệm này cho thấy rằng khối lượng ý tưởng khổng lồ có thể bù đắp cho việc thiếu “gu”. Nếu AARs có thể chạy nhiều thử nghiệm với chi phí rất thấp, có thể chúng có thể “vét cạn” để tìm ra những phát hiện mà một nhà nghiên cứu có gu rất cao có thể đã nghĩ ra, hoặc tìm thấy thành công theo những hướng mà các nhà nghiên cứu đó có thể đã từ bỏ.
Đổi lại, điều này có nghĩa là nút thắt cổ chai cốt lõi trong nghiên cứu căn chỉnh có thể trở thành đánh giá (đảm bảo rằng các thử nghiệm được thiết lập đủ tốt để chúng ta tin tưởng vào kết quả của chúng), thay vì tạo ra (dựa vào các nhà nghiên cứu con người để đề xuất các ý tưởng hứa hẹn).
Khoa học ngoài hành tinh. Công việc này cũng có thể có một số ý nghĩa kỳ lạ hơn. AARs, về bản chất, được thiết kế để khám phá những ý tưởng mà con người có thể chưa từng xem xét. Nhưng chúng ta vẫn cần một cách để xác minh liệu ý tưởng và kết quả của chúng có đúng đắn hay không. Hiện tại, chúng ta vẫn có thể diễn giải những gì các AAR đã làm và tại sao. Nhưng điều đó có thể không phải lúc nào cũng đúng: theo thời gian, các ý tưởng của mô hình có thể trở nên khó xác minh hơn nhiều, hoặc bị hỏng theo những cách khó để con người phân tích hoặc phát hiện. Điều đó có thể có nghĩa là tạo ra một “khoa học ngoài hành tinh”.
Ngăn chặn các cuộc tấn công
