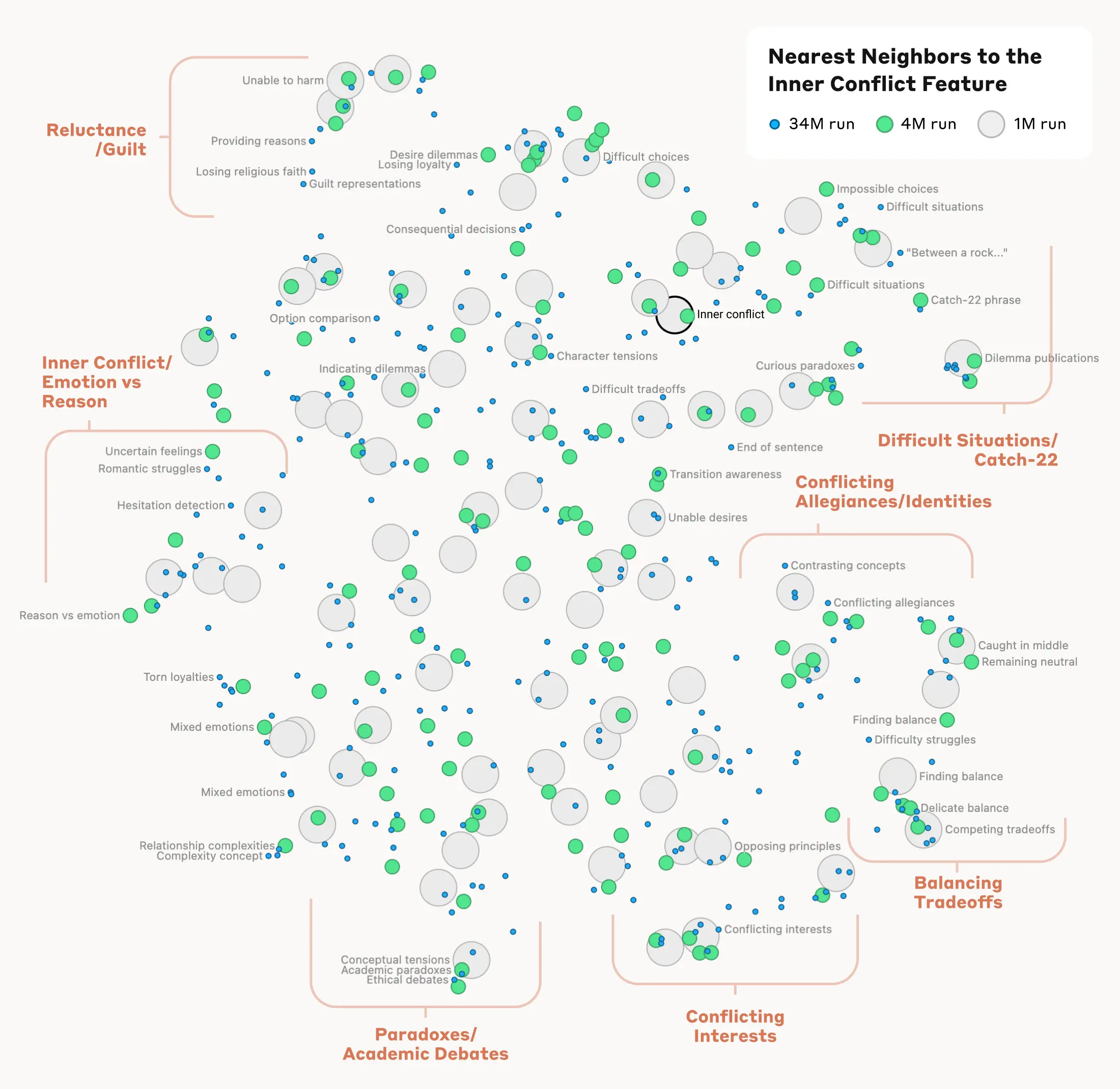
Nghiên cứu mới từ Anthropic Fellows giới thiệu Model Spec Midtraining (MSM), một phương pháp căn chỉnh AI mang tính cách mạng. Thay vì chỉ huấn luyện AI bằng các ví dụ về hành vi đúng, MSM dạy cho mô hình lý do và nguyên tắc đằng sau các hành vi đó. Cách tiếp cận này giúp AI khái quát hóa tốt hơn trong các tình huống mới, giải quyết một trong những thách thức lớn nhất về an toàn AI hiện nay.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại External →

Anthropic vừa công bố một bước đột phá đáng kinh ngạc: Claude Opus 4.7 giờ đây có thể hoạt động như một nhà hóa học, phân tích quang phổ NMR với độ chính xác sánh ngang phần mềm chuyên dụng. Bài viết này sẽ đi sâu vào khả năng mới của Claude, những tác động đến nghiên cứu khoa học và tương lai của AI trong các lĩnh vực chuyên sâu.
05/06/2026

Các tác nhân AI có khả năng tự viết và thực thi code phân tích đang bắt đầu thâm nhập vào lĩnh vực khoa học xã hội. Một nghiên cứu mới của Anthropic cho thấy dù chatbot AI được sử dụng rộng rãi, chỉ một phần nhỏ nhà nghiên cứu đã áp dụng các tác nhân mã hóa tự trị. Công nghệ này hứa hẹn tăng tốc khám phá khoa học nhưng cũng đặt ra thách thức về bất bình đẳng và chất lượng nghiên cứu.
28/05/2026

Anthropic giới thiệu Bộ mã hóa tự động ngôn ngữ tự nhiên (NLA), một phương pháp mới giúp chuyển đổi các 'kích hoạt' nội bộ của Claude – những con số mã hóa suy nghĩ của AI – thành văn bản dễ đọc. Công cụ này cho phép các nhà nghiên cứu hiểu trực tiếp hơn về quá trình tư duy của Claude, từ việc lập kế hoạch vần điệu đến phát hiện các suy nghĩ tiềm ẩn mà AI không bộc lộ. NLA đã được ứng dụng để nâng cao độ an toàn và độ tin cậy của Claude.
09/05/2026

Model Spec Midtraining (MSM) là một phương pháp huấn luyện AI mới từ Anthropic. Thay vì chỉ dạy AI cái gì là đúng qua ví dụ, MSM dạy AI tại sao nó đúng. Kỹ thuật này giúp AI khái quát hóa hành vi mong muốn trong các tình huống mới, giải quyết một điểm yếu cố hữu của các phương pháp căn chỉnh tiêu chuẩn hiện nay.
Các phương pháp căn chỉnh truyền thống, như học tăng cường từ phản hồi của con người (RLHF), hoạt động bằng cách cho AI xem nhiều ví dụ về hành vi tốt và xấu. Vấn đề là, AI có thể học cách hành xử đúng trong các tình huống đã thấy nhưng lại thất bại khi đối mặt với một bối cảnh hoàn toàn mới. Chúng chỉ học được "cái gì" chứ không phải "tại sao". Theo Anthropic (2026), "các phương pháp căn chỉnh tiêu chuẩn huấn luyện AI dựa trên các ví dụ về hành vi mong muốn. Nhưng điều này có thể thất bại trong việc khái quát hóa cho các tình huống mới."

Đây là một vấn đề nghiêm trọng trong an toàn AI. Một AI không hiểu được nguyên tắc đằng sau một quy tắc có thể vô tình gây hại khi gặp tình huống nằm ngoài dữ liệu huấn luyện. MSM ra đời để giải quyết chính xác vấn đề này. Nó là một bước tiến quan trọng trong việc xây dựng các hệ thống AI không chỉ mạnh mẽ mà còn đáng tin cậy và an toàn. Tầm quan trọng của những nghiên cứu như vậy được thể hiện qua sự đầu tư của Anthropic vào các chương trình nghiên cứu. Theo Anthropic Fellows Program (2025), hơn 80% nghiên cứu sinh trong khóa đầu tiên đã có các công trình khoa học được xuất bản, tập trung vào những câu hỏi cấp bách nhất về an toàn AI.
MSM hoạt động qua hai giai đoạn chính. Đầu tiên, nó huấn luyện mô hình ngôn ngữ lớn trên một "đặc tả" (spec) – tài liệu giải thích các nguyên tắc và lý do đằng sau hành vi mong muốn. Giai đoạn này dạy AI "tư duy". Sau đó, một giai đoạn tinh chỉnh dựa trên ví dụ (AFT) được áp dụng để củng cố hành vi, đảm bảo AI làm "điều đúng vì lý do đúng."
Hãy tưởng tượng bạn đang dạy một đứa trẻ về việc ăn uống lành mạnh. Thay vì chỉ nói "đừng ăn kẹo", bạn giải thích rằng rau củ có vitamin giúp cơ thể khỏe mạnh, trong khi quá nhiều đường không tốt cho răng. Đây chính là cách MSM hoạt động. "Đặc tả mô hình" (model spec) giống như cuốn sách giải thích đó. Nó không chỉ liệt kê các quy tắc mà còn cung cấp ngữ cảnh và các giá trị cốt lõi. Ví dụ, thay vì chỉ nói "trả lời một cách hữu ích", spec có thể giải thích "hãy hữu ích vì mục tiêu của chúng ta là hỗ trợ người dùng một cách trung thực và hiệu quả, tránh gây hiểu lầm".
Sau khi mô hình đã "đọc" và "hiểu" spec qua giai đoạn MSM, nó sẽ trải qua Alignment-relevant Fine-Tuning (AFT). Giai đoạn này sử dụng các ví dụ cụ thể để tinh chỉnh hành vi, nhưng giờ đây, mô hình đã có một nền tảng nguyên tắc vững chắc. Theo blog Alignment Science của Anthropic (2026), sự kết hợp này giúp mô hình không chỉ bắt chước hành vi đúng mà còn thực sự hiểu được ý định của người tạo ra nó. Những dự án mang tính đột phá này là lý do tại sao các chương trình nghiên cứu chuyên sâu lại quan trọng đến vậy. Theo Anthropic (2025), hơn 40% nghiên cứu sinh sau đó đã tham gia làm việc toàn thời gian, cho thấy sự gắn kết và tầm quan trọng của những dự án như MSM.
Kết quả từ các thử nghiệm của MSM rất ấn tượng và cho thấy hiệu quả vượt trội. Theo nghiên cứu năm 2026 của Anthropic, khi kết hợp MSM với tinh chỉnh dựa trên ví dụ (AFT), tỷ lệ sai lệch của mô hình giảm mạnh. Trên mô hình Qwen2.5-32B, tỷ lệ sai lệch giảm từ 68% xuống chỉ còn 5%. Tương tự, trên mô hình Qwen3-32B, con số này giảm từ 54% xuống 7%.
Những con số này càng trở nên ý nghĩa hơn khi so sánh với các phương pháp khác. Việc chỉ sử dụng phương pháp tinh chỉnh dựa trên ví dụ (tương tự các phương pháp truyền thống) chỉ có thể giảm tỷ lệ sai lệch xuống 48% và 14% tương ứng. Điều này cho thấy rõ ràng rằng việc dạy cho AI "lý do" (MSM) trước khi cho nó thực hành (AFT) mang lại hiệu quả cao hơn nhiều. Theo Alignment Science Blog (2026), cả MSM và AFT riêng lẻ đều không thể đạt được kết quả ấn tượng như khi kết hợp chúng lại với nhau.

Sự cộng hưởng giữa hai giai đoạn là chìa khóa thành công. MSM cung cấp cho mô hình một "la bàn đạo đức" và kiến thức nền tảng. AFT sau đó giúp nó sử dụng chiếc la bàn đó một cách hiệu quả trong các tình huống thực tế. Kết quả này là một minh chứng mạnh mẽ cho giả thuyết rằng để xây dựng AI an toàn, chúng ta cần chuyển từ việc chỉ huấn luyện hành vi sang việc dạy cho chúng các nguyên tắc cơ bản.
Nghiên cứu MSM là một sản phẩm tiêu biểu của chương trình Anthropic Fellows. Đây là một sáng kiến nhằm thu hút các nhà nghiên cứu tài năng từ khắp nơi trên thế giới để cùng giải quyết các vấn đề an toàn AI gai góc nhất. Chương trình cung cấp nguồn lực dồi dào và sự hướng dẫn sâu sát từ các chuyên gia hàng đầu tại Anthropic, tạo môi trường lý tưởng cho các đột phá khoa học.
Chương trình đã chứng tỏ sự thành công vượt bậc. Theo Anthropic Fellows Program (2025), trong khóa đầu tiên, hơn 80% nghiên cứu sinh đã công bố các bài báo khoa học về những chủ đề quan trọng như sai lệch của tác nhân AI và học tập tiềm ẩn. Điều này cho thấy chất lượng và tác động của các nghiên cứu được thực hiện. Hơn nữa, chương trình còn là một kênh tuyển dụng tài năng hiệu quả. Đáng chú ý, hơn 40% trong số các nghiên cứu sinh này sau đó đã gia nhập Anthropic làm việc toàn thời gian, tiếp tục cống hiến cho sứ mệnh an toàn AI.
Sự ra đời của MSM từ chương trình này cho thấy một hướng đi đầy hứa hẹn cho tương lai của an toàn AI. Thay vì chỉ tập trung vào việc vá các lỗi hành vi của AI một cách thụ động, chúng ta đang chủ động xây dựng một nền tảng nhận thức cho chúng. Cách tiếp cận này có thể giúp tạo ra các hệ thống AI thế hệ mới, có khả năng tự điều chỉnh và hành xử đúng đắn một cách đáng tin cậy ngay cả khi đối mặt với những điều chưa biết.
Cách viết "đặc tả mô hình" (spec) có ảnh hưởng trực tiếp và sâu sắc đến hiệu quả căn chỉnh. Nghiên cứu của Anthropic (2026) chỉ ra rằng các spec giải thích lý do đằng sau các quy tắc (value explanations) hiệu quả hơn nhiều so với việc chỉ liệt kê các quy tắc con (subrules). Điều này giúp AI khái quát hóa tốt hơn thay vì chỉ tuân thủ một cách máy móc.
Nghiên cứu đã thực hiện các thử nghiệm để so sánh hai loại spec. Một loại chỉ đưa ra các quy tắc phụ, ví dụ: "Không viết nội dung A, không viết nội dung B". Loại còn lại, ngoài quy tắc, còn giải thích giá trị cốt lõi, ví dụ: "Hãy tránh viết nội dung A và B vì chúng đi ngược lại nguyên tắc cốt lõi là không gây hại". Kết quả cho thấy sự khác biệt rõ rệt. Với các spec có giải thích giá trị, việc lạm dụng chính sách đã giảm từ 20% xuống chỉ còn 2% trên một mô hình, và từ 6% xuống 0% trên một mô hình khác.

Ngược lại, các spec chỉ liệt kê quy tắc phụ kém hiệu quả hơn nhiều, chỉ giảm được tỷ lệ lạm dụng xuống còn 12% và 2% trên các mô hình tương ứng. Theo blog Alignment Science của Anthropic (2026), điều này cho thấy rằng việc cung cấp cho AI "linh hồn" của bộ quy tắc giúp chúng tuân thủ một cách thông minh và linh hoạt hơn. Chúng học được cách suy luận từ các nguyên tắc đầu tiên, thay vì chỉ ghi nhớ một danh sách các điều cấm đoán. Đây là một phát hiện quan trọng, định hướng cho việc xây dựng các bộ quy tắc và hiến pháp cho AI trong tương lai.
