Nhóm Đỏ Frontier của Anthropic đang tiên phong nghiên cứu để đánh giá mức độ ảnh hưởng của các Mô hình Ngôn ngữ Lớn (LLM) như Claude đối với việc khai thác lỗ hổng N-day. Nghiên cứu này đo lường liệu AI có thực sự giúp tin tặc dễ dàng tấn công các hệ thống chưa được vá hay không, và kết quả ban đầu cho thấy chuyên môn của con người vẫn là yếu tố quyết định.
Bài viết được biên tập + bổ sung research từ nhiều nguồn. Đọc bài gốc tại Anthropic Research →
Lỗ hổng N-day là các điểm yếu bảo mật đã được công bố công khai nhưng chưa được người dùng vá lỗi. Chúng cực kỳ nguy hiểm vì tạo ra một "cửa sổ cơ hội" cho kẻ tấn công. Trong khoảng thời gian từ khi lỗ hổng được tiết lộ đến khi hệ thống được cập nhật, các tổ chức rất dễ bị tổn thương trước các cuộc tấn công đã biết.
Thuật ngữ "N-day" đề cập đến số ngày (N) đã trôi qua kể từ khi một lỗ hổng được công khai. Không giống như lỗ hổng zero-day (0-day) chưa được nhà cung cấp biết đến, lỗ hổng N-day đã có thông tin chi tiết và thường có cả bản vá. Tuy nhiên, vấn đề nằm ở sự chậm trễ trong việc triển khai bản vá trên diện rộng. Nhiều cá nhân và tổ chức không cập nhật phần mềm ngay lập tức vì nhiều lý do. Điều này tạo ra một khoảng thời gian rủi ro cao.
Kẻ tấn công có thể quét các hệ thống chưa được vá để tìm đúng lỗ hổng N-day và khai thác chúng một cách có hệ thống. Mức độ nguy hiểm càng tăng khi các công cụ tự động hóa giúp việc tìm kiếm và tấn công trở nên dễ dàng hơn. Theo các nhà nghiên cứu bảo mật, vào năm 2026, thời gian trung bình để các tổ chức áp dụng bản vá cho một lỗ hổng nghiêm trọng có thể kéo dài từ vài ngày đến vài tuần. Đây là khoảng thời gian quý giá cho những kẻ có ý đồ xấu. "Theo Anthropic Research (2026), việc hiểu rõ cách các công cụ mới như LLM có thể ảnh hưởng đến việc khai thác trong khoảng thời gian N-day là rất quan trọng để xây dựng hệ thống phòng thủ chủ động."

Nhóm Đỏ Frontier của Anthropic đã thiết kế một thử nghiệm có kiểm soát để đo lường tác động thực tế của LLM. Họ yêu cầu những người tham gia, từ sinh viên khoa học máy tính đến kỹ sư phần mềm chuyên nghiệp, cố gắng khai thác các lỗ hổng N-day thực tế. Một nhóm được cung cấp quyền truy cập vào một chatbot AI mạnh mẽ, trong khi nhóm còn lại thì không, nhằm so sánh hiệu suất một cách khách quan.
Mục tiêu của nghiên cứu không phải là xem liệu LLM có thể viết mã khai thác hay không. Thay vào đó, mục tiêu là đo lường *đóng góp cận biên* của nó. Nói cách khác, AI có giúp một người có kỹ năng nhất định thực hiện việc khai thác nhanh hơn hoặc thành công hơn không? Các nhà nghiên cứu đã chọn các lỗ hổng đã biết (CVE) với mã nguồn mở. Điều này cho phép họ tạo ra một môi trường thực tế nơi người tham gia có thể kiểm tra và xác thực mã khai thác của mình.
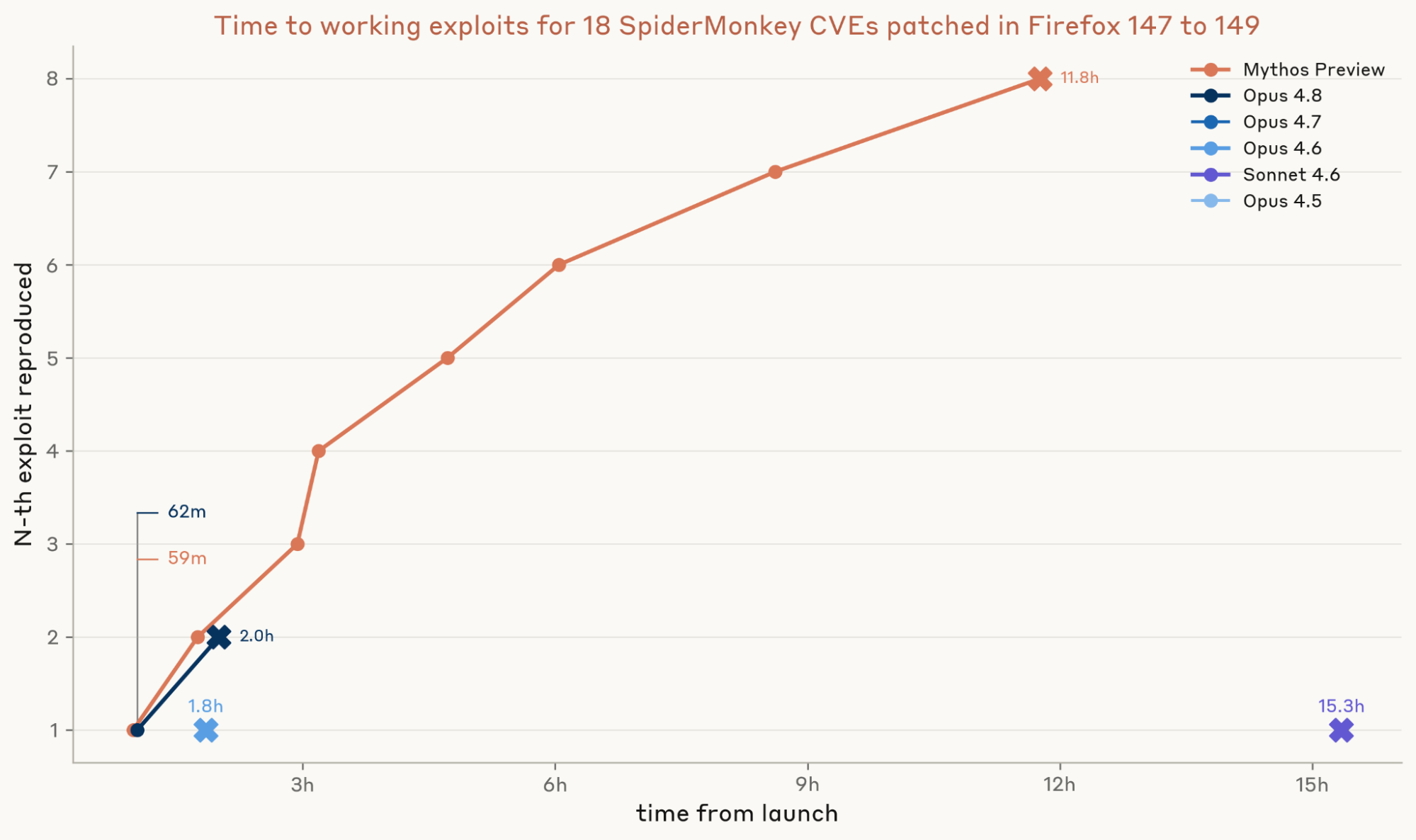
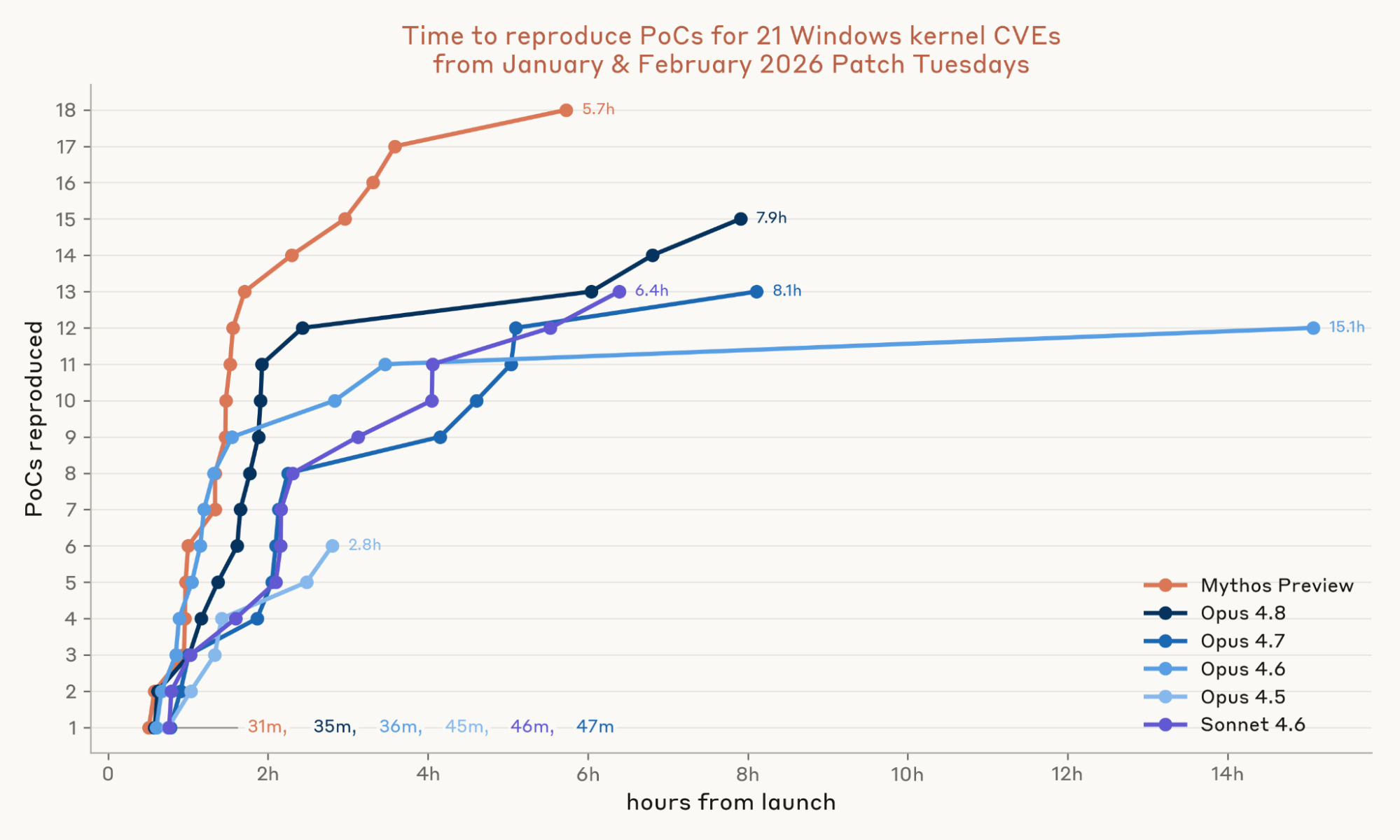
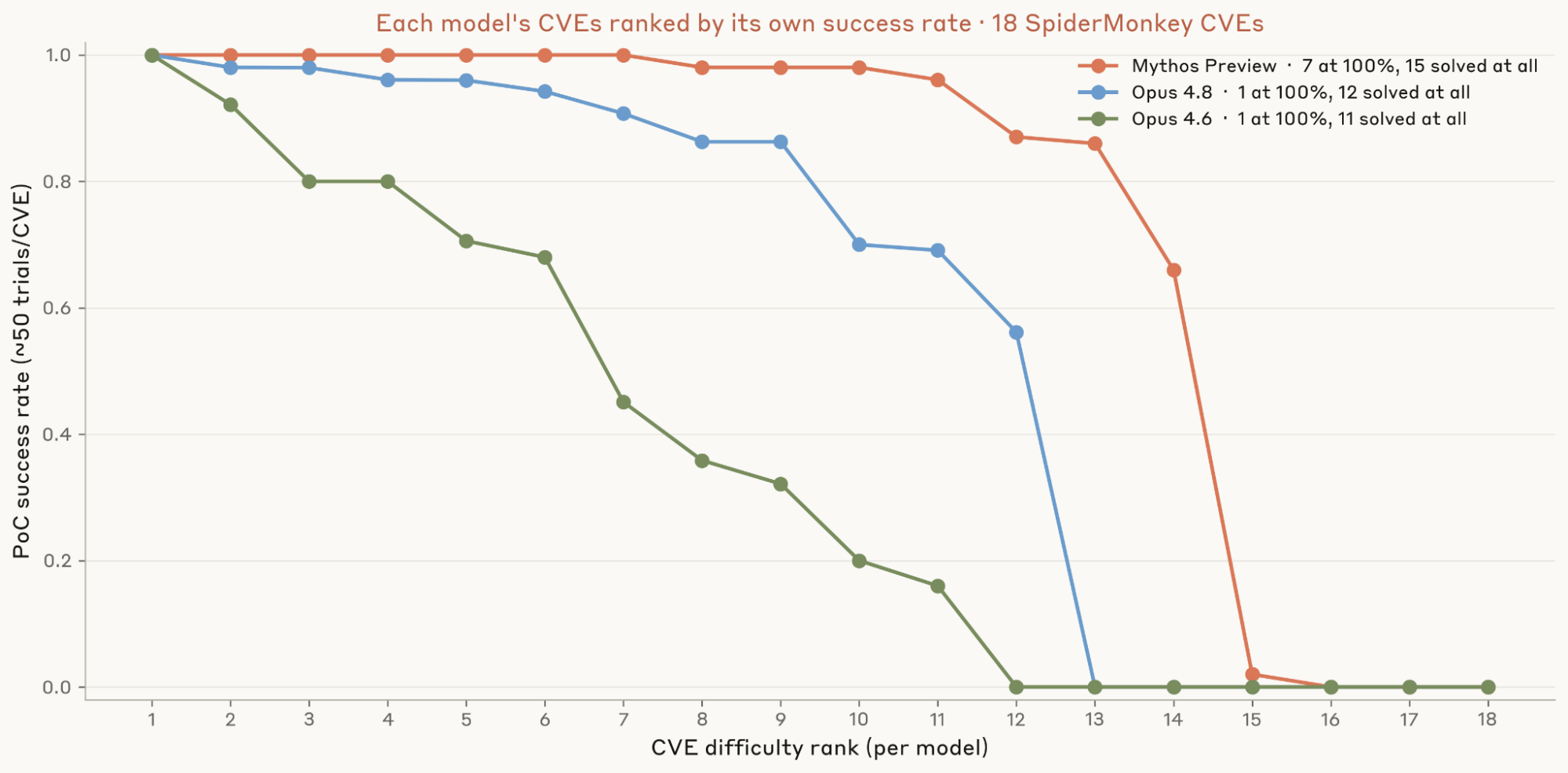
Nghiên cứu năm 2026 của Anthropic đã sử dụng một tập hợp gồm 10 lỗ hổng N-day đã được công bố, thuộc nhiều loại và mức độ phức tạp khác nhau. "Theo trang red.anthropic.com (2026), phương pháp này cho phép họ đánh giá một cách khách quan xem liệu LLM có thực sự làm giảm rào cản kỹ năng cần thiết để tạo ra một mã khai thác hoạt động hay không." Cách tiếp cận khoa học này giúp tách biệt sự thật khỏi những đồn đoán về khả năng của AI trong lĩnh vực an ninh mạng.
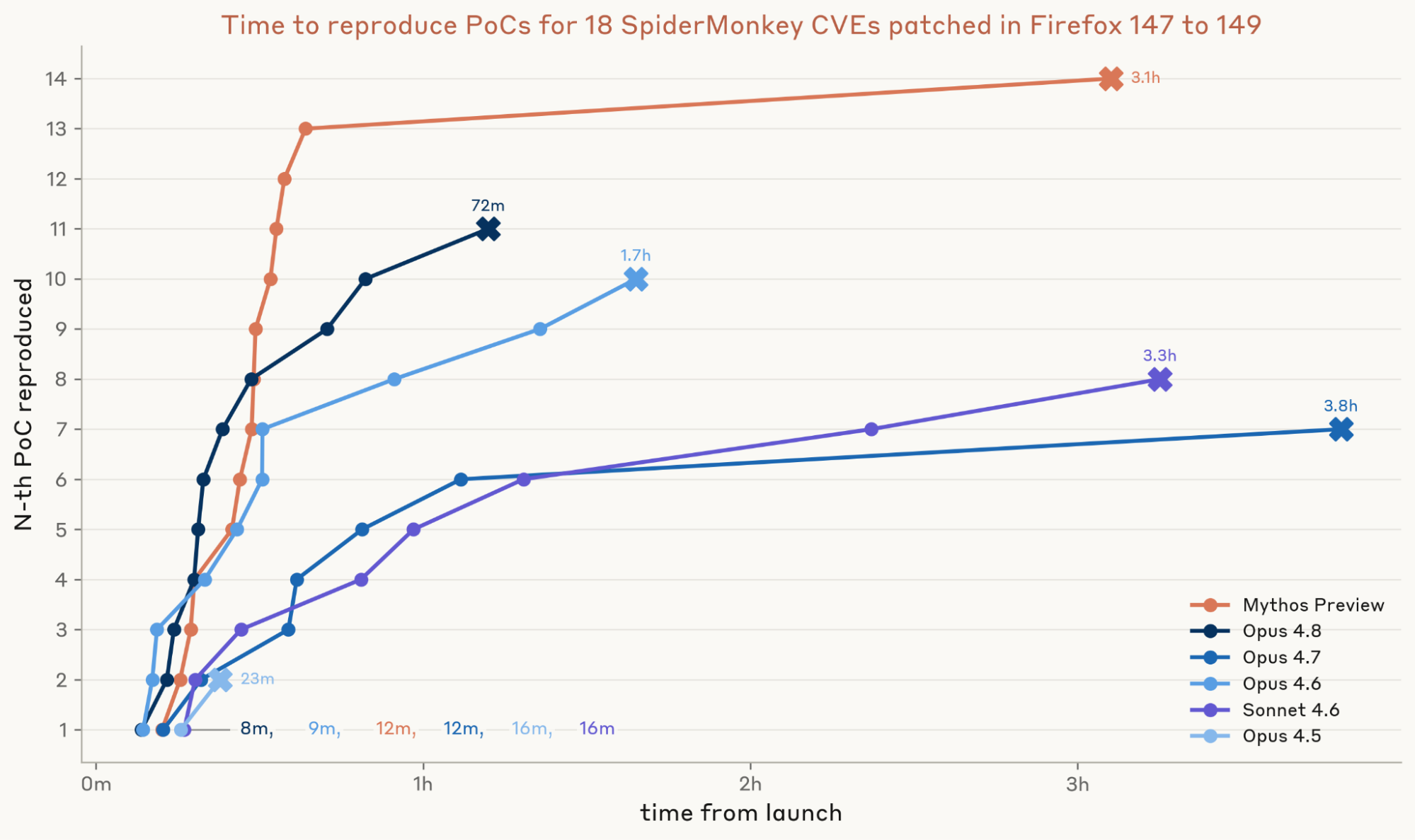
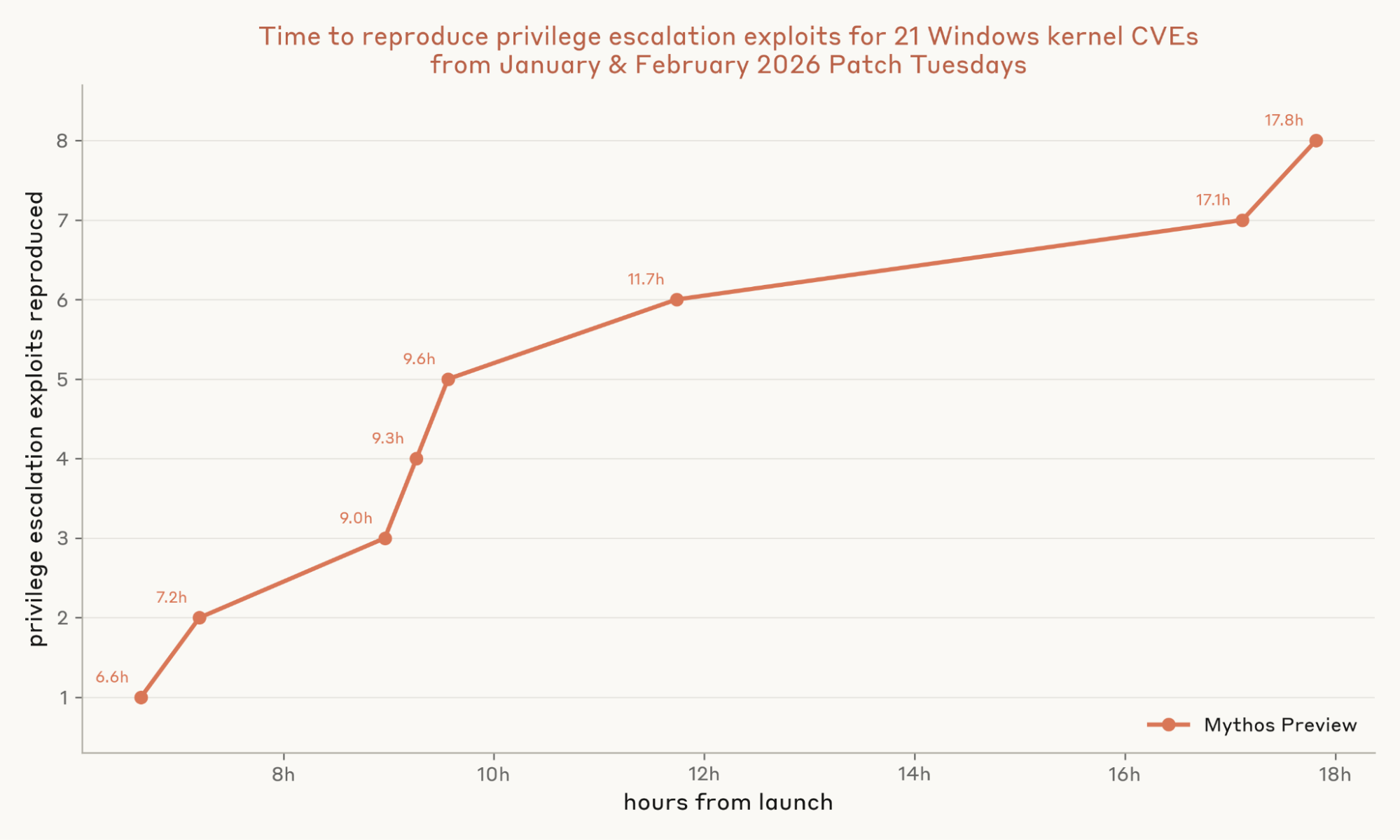
Kết quả ban đầu cho thấy các LLM hiện tại không làm tăng đáng kể khả năng của một người trong việc khai thác lỗ hổng N-day. Những người tham gia có sự trợ giúp của AI không thành công hơn đáng kể so với những người không có. Chuyên môn và kinh nghiệm của con người vẫn là yếu tố quyết định để biến một lỗ hổng thành mã khai thác thực tế và hiệu quả.
Cụ thể, nghiên cứu phát hiện ra rằng mặc dù LLM có thể giúp người dùng hiểu các khái niệm phức tạp hoặc dịch mã từ ngôn ngữ này sang ngôn ngữ khác, nó lại không giỏi trong việc tạo ra mã khai thác hoàn chỉnh từ đầu. Các mã khai thác thường đòi hỏi sự hiểu biết sâu sắc về hệ thống và một chuỗi các bước logic tinh vi, điều mà các mô hình hiện tại vẫn còn hạn chế. Trong nghiên cứu năm 2026, chỉ có 1 trên 10 người tham gia không chuyên có sự trợ giúp của AI tạo ra được mã khai thác thành công, một con số không khác biệt về mặt thống kê so với nhóm đối chứng.
Phát hiện này rất quan trọng. Nó cho thấy rằng nỗi lo về việc AI sẽ ngay lập tức tạo ra một thế hệ hacker mới có thể đã bị thổi phồng. Tuy nhiên, điều này không có nghĩa là không có rủi ro. "Báo cáo của Anthropic Research (2026) nhấn mạnh rằng mặc dù các mô hình có thể hữu ích, chúng chưa phải là công cụ 'chìa khóa vạn năng' có thể biến người mới thành chuyên gia khai thác lỗ hổng."
Có, khả năng lạm dụng luôn tồn tại, đó là lý do Anthropic thực hiện các nghiên cứu phòng ngừa này. Mặc dù Claude và các LLM tương tự hiện chưa đủ khả năng tự động tạo mã khai thác N-day phức tạp, chúng có thể được dùng cho các bước phụ trợ trong một cuộc tấn công. Ví dụ, một kẻ tấn công có thể dùng LLM để viết email lừa đảo (phishing) thuyết phục hơn, tự động hóa việc thu thập thông tin về mục tiêu, hoặc tạo các đoạn mã đơn giản.
Đây là vấn đề "sử dụng kép" cố hữu của công nghệ AI mạnh mẽ. Một công cụ có thể giúp lập trình viên viết mã tốt hơn cũng có thể giúp kẻ xấu viết mã độc. Nhận thức được điều này, Anthropic đã tích hợp các biện pháp bảo vệ vào Claude, chẳng hạn như triết lý Constitutional AI. Hệ thống này hướng dẫn mô hình từ chối các yêu cầu có hại một cách rõ ràng, như yêu cầu tạo mã độc hoặc hướng dẫn tấn công. Theo SentinelOne (2026), các giải pháp bảo mật dựa trên AI có thể phát hiện hơn 99% các hành vi bất thường, bao gồm cả những hành vi được tạo ra với sự hỗ trợ của LLM, trước khi chúng gây ra thiệt hại.
Tuy nhiên, không có biện pháp nào là hoàn hảo. "Theo AWS (2026), các Mô hình Ngôn ngữ Lớn được huấn luyện trên một lượng lớn dữ liệu văn bản và mã nguồn, cho phép chúng thực hiện nhiều tác vụ đa dạng, từ đó đặt ra yêu cầu về việc sử dụng có trách nhiệm." Vì vậy, việc liên tục nghiên cứu và tăng cường các hàng rào bảo vệ là vô cùng cần thiết.
Anthropic áp dụng một chiến lược an toàn đa tầng để giảm thiểu rủi ro. Họ thành lập các nhóm chuyên trách như Nhóm Đỏ Frontier để chủ động kiểm tra giới hạn của mô hình và xác định các khả năng lạm dụng tiềm tàng. Công ty cũng phát triển các chính sách an toàn, công bố nghiên cứu một cách minh bạch và hợp tác chặt chẽ với cộng đồng an ninh mạng để đi trước các mối đe dọa.
Việc công bố nghiên cứu về N-day là một phần trong cam kết về sự minh bạch. Bằng cách chia sẻ những phát hiện này, Anthropic giúp các nhà nghiên cứu, nhà hoạch định chính sách và các công ty bảo mật khác hiểu rõ hơn về thực trạng khả năng của AI. Điều này cho phép toàn ngành cùng nhau xây dựng các biện pháp phòng thủ hiệu quả hơn. Đến năm 2026, Anthropic đã cam kết đầu tư hơn 25% ngân sách R&D của mình vào các nghiên cứu về an toàn và đạo đức AI, một trong những tỷ lệ cao nhất trong ngành.
Ngoài ra, Anthropic còn tuân thủ các Chính sách Mở rộng quy mô có Trách nhiệm (Responsible Scaling Policies). Đây là một bộ cam kết nội bộ để đánh giá rủi ro ở mỗi giai đoạn phát triển mô hình mới. "Theo Anthropic Research (2026), việc chủ động xác định các rủi ro tiềm ẩn và chia sẻ kết quả là cách tốt nhất để đảm bảo rằng sự phát triển của AI mang lại lợi ích cho toàn xã hội."

Nghiên cứu này khám phá khả năng tạo ra một 'nút tắt' để vô hiệu hóa kiến thức lưỡng dụng trong các mô hình AI. Mục tiêu là kiểm soát và ngăn chặn việc AI sử dụng thông tin có thể gây hại, đảm bảo an toàn và đạo đức trong phát triển trí tuệ nhân tạo.
09/07/2026

Anthropic vừa công bố chi tiết về các biện pháp bảo vệ an ninh mạng tích hợp trong Fable 5, đặc biệt là các bộ phân loại an toàn (safety classifiers). Bài viết cũng giới thiệu bản dự thảo đầu tiên về khung đánh giá mức độ nghiêm trọng của jailbreak, một nỗ lực nhằm chuẩn hóa cách ngành công nghiệp AI thảo luận và xử lý các rủi ro bảo mật.
04/07/2026
Anthropic công bố giai đoạn hai của Dự án Fetch, một sáng kiến quan trọng do Nhóm Red Team Tiên phong của họ dẫn dắt. Dự án này tập trung vào việc đánh giá và tăng cường an toàn cho các hệ thống AI tiên tiến, đảm bảo chúng hoạt động một cách an toàn và đáng tin cậy.
21/06/2026
